
Давно мы не писали о Django! Последняя статья — "Django 44. Отправка электронной почты в фоновом режиме" — вышла более полугода назад. С тех пор функциональные изменения на сайте были минимальными, если не считать новый дизайн статей и несколько связанных с ним доработок.
В этой статье я хочу поделиться сразу тремя небольшими, но крайне полезными улучшениями:
- Оглавление статьи. Этот функционал давно просили, особенно авторы. Наши статьи стали длиннее и более структурированными, поэтому оглавление — это удобный инструмент для навигации.
- Кнопка "Вернуться наверх". После добавления оглавления я осознал, что не хватает возможности быстро вернуться к началу страницы, особенно на длинных статьях.
- Кнопки "Поделиться в социальных сетях". Этот запрос поступал от читателей. Многие отмечали, что удобнее отправить статью другу или сохранить ссылку на свою страницу в соцсети с помощью одной кнопки.
Все эти пожелания я учёл и реализовал! В статье я расскажу, как это было сделано, и вы сможете легко внедрить такие же улучшения в своих проектах. Поехали!
Автоматическая генерация оглавления статьи
Когда наш сайт только появился, то подвергнуть каждую статью полному циклу постобработки (редактура, подбор кода, подготовка скриншотов, перевод из Markdown в HTML и прочее) - было лучшим решением, потому что материалы нужно было публиковать, а производство сайта и так заняло много времени и сил.
Сейчас, когда появилось определенное понимание какие процессы и каким именно образом можно оптимизировать, а также, когда количество публикацией приблизилось к двумстам (200), то лучшим решением будет создать алгоритм, который снимет часть операционной работы с модератора. Такой алгоритм должен формировать оглавление на основе содержимого статьи.
Принцип работы такой:
- Добавление нового поля в модель статьи.
В модель статьи добавляем поле для хранения актуального оглавления. Это снизит нагрузку на базу данных: вместо генерации оглавления "на лету", оно будет формироваться при сохранении объекта модели и сохраняться в специальное поле. - Настройка Django-сигнала.
Создадим сигнал, который будет срабатывать при сохранении объекта модели статьи. - Парсинг HTML-текста. Внутри сигнала вызовем функцию, которая:
- Проанализирует HTML-контент статьи.
- Найдёт заголовки
H2-H5. - Добавит к ним уникальные идентификаторы
idдля ссылок. - Построит "дерево" оглавления, учитывая вложенность заголовков.
- Обновление полей модели.
После выполнения парсинга сигнал обновит текст статьи, добавив к заголовкам атрибутыid, и сохранит дерево оглавления в соответствующее поле. - Вывод оглавления в шаблоне.
В шаблоне статьи, используя рекурсию, выведем дерево оглавления, сохраняя отступы для визуального отображения вложенности.
Простой и эффективный подход! Пора приступать к реализации. 🚀
Почему мы обрабатываем только H2-H5?
Дело в том, что заголовки в HTML имеют строго иерархическую структуру. Это может показаться несущественным для человека, но для поисковых систем такая структура играет ключевую роль!
- На странице должен быть только один тег
H1, который обозначает главный заголовок страницы. Этот заголовок служит основным ориентиром для поисковиков и пользователей. - Заголовки
H2и ниже создают дерево вложенности. Например:- Теги
H3могут находиться только внутри разделов, обозначенныхH2. - Теги
H4— только внутриH3. - И так далее вплоть до
H5.
- Теги
Таким образом, заголовки не только придают структуру странице, но и указывают на относительную важность информации. Благодаря этому поисковые системы понимают содержание документа и его иерархию, что влияет на SEO.
Обрабатывая только H2-H5, мы сохраняем эту иерархию и упрощаем навигацию для читателей.
Поле table_of_contents в модели статьи
В приложении blog откроем файл models.py и найдём класс PostModel. Мы начали его писать в статье "Django 20. Модель поста".
Добавим в него новое поле table_of_contents с типом models.JSONField. Использование JSON-поля позволяет удобно сохранять дерево заголовков с учётом их вложенности.
Чтобы избежать ошибок и сделать поле гибким, укажем параметры blank=True и null=True. Это важно по двум причинам:
- Отсутствие оглавления сразу после сохранения.
Поскольку оглавление формируется автоматически, его значение будет пустым до вызова специальной функции. - Существующие статьи на сайте.
У уже опубликованных статей оглавление не будет сгенерировано автоматически. Указание поля как необязательного позволяет избежать ошибок при обновлении модели. Чтобы добавить оглавление к таким статьям, достаточно пересохранить их через админку.
Код поля:
table_of_contents = models.JSONField(blank=True, null=True)Теперь модель готова к работе с автоматически генерируемыми оглавлениями.
Сигнал generate_table_of_contents
О том, как работать с сигналами в Django, я подробно писал в статье Django 35.1. Расширенный профиль пользователя — модель и сигналы. Если вы не знакомы с этой темой, рекомендую сначала освежить эти знания.
Теперь перейдём к созданию сигнала для генерации оглавления.
Шаг 1: Подготовка файла signals.py
В приложении blog откройте файл signals.py. Если его ещё нет, создайте. Этот файл будет содержать все ваши сигналы для данного приложения.
Шаг 2: Декоратор и сигнал
Для начала, пропишем декоратор @receiver(). Если в прошлый раз мы использовали сигнал post_save (для выполнения действий после сохранения объекта), то в этот раз будем использовать pre_save. Этот сигнал срабатывает до сохранения объекта, что позволит обновить данные модели ещё до их записи в базу данных. В декораторе указываем модель PostModel как отправителя.
@receiver(pre_save, sender=PostModel)
Шаг 3: Функция сигнала
Затем создаём функцию generate_table_of_contents. Она принимает следующие аргументы:
sender— модель, которая отправляет сигнал;instance: PostModel— объект модели, для которого выполняется сохранение;**kwargs— дополнительные параметры, которые мы в данном случае использовать не будем.
def generate_table_of_contents(sender, instance: PostModel, **kwargs):
В функции сначала проверяем, есть ли текст статьи. Хотя поле full_body (основной текст статьи) является обязательным, эта проверка защитит от возможных исключений, если текст отсутствует.
Если текст есть, вызываем функцию parse_article_content, которая:
- Парсит HTML-текст статьи.
- Добавляет уникальные
idк заголовкам. - Формирует список словарей для оглавления.
Возвращаемые значения функции:
html— обновлённый текст статьи с добавленнымиidдля заголовков.toc— дерево оглавления, готовое для записи в полеtable_of_contents.
Обновляем поля модели: full_body и table_of_contents.
Код сигнала:
from django.db.models.signals import pre_save
from django.dispatch import receiver
from blog.models import PostModel
from blog.utils import parse_article_content
@receiver(pre_save, sender=PostModel)
def generate_table_of_contents(sender, instance: PostModel, **kwargs):
if instance.full_body:
html, toc = parse_article_content(instance.full_body)
instance.full_body = html
instance.table_of_contents = toc
Пояснение ключевых моментов:
- Почему
pre_save, а неpost_save?
Мы используемpre_save, чтобы изменения полей модели (например, обновление текста и оглавления) сохранялись в базе данных одновременно с объектом. Если использоватьpost_save, нам пришлось бы дополнительно вызывать методsave(), что могло бы привести к рекурсии. - Функция
parse_article_contentбудет описана далее.
Именно она берёт на себя всю тяжёлую работу: парсинг HTML, добавлениеidк заголовкам и построение дерева оглавления.
Теперь, когда сигнал готов, можно перейти к реализации функции парсинга контента.
Парсинг содержимого статьи
Так как статья представлена в виде HTML-текста благодаря визуальному редактору, о котором я рассказывал в статье "Django 19. Визуальный редактор CKEditor5", нам необходимо "распарсить" её содержимое. Задача — получить все заголовки с учётом их вложенности, добавить к ним уникальные id и сохранить структуру в виде списка словарей.
Для работы с HTML мы будем использовать библиотеку beautifulsoup4.
Почему BeautifulSoup4?
Выбор библиотеки beautifulsoup4 (BS4) для парсинга HTML обусловлен её гибкостью, простотой и мощным инструментарием для работы с разметкой. В отличие от ручного разбора через регулярные выражения, BS4 предоставляет интуитивно понятный API для навигации по DOM-дереву, поиска тегов и их атрибутов. Это особенно важно при обработке пользовательского контента из CKEditor5, где структура HTML может быть неидеальной или изменяться со временем.
BS4 отлично справляется с:
- Извлечением данных — поиск всех заголовков (
h2-h5) выполняется одной строкой кода черезfind_all(). - Модификацией контента — добавление
idк тегам происходит "на лету" без сложных манипуляций с текстом. - Работой с "грязным" HTML — встроенные парсеры (как
html.parser) корректно обрабатывают незакрытые теги и другие аномалии.
Библиотека идеально вписывается в контекст генерации оглавления, превращая рутинную работу с HTML в предсказуемый процесс с минимальным количеством кода.
Установить её можно командой:
pip install beautifulsoup4
Не забудьте также зафиксировать библиотеку в файле requirements.txt:
beautifulsoup44.12.3
Теперь перейдём к написанию функции-парсера. Создайте в приложении blog новый файл utils.py и откройте его.
Объявим функцию parse_article_content, которая принимает один аргумент content — текст статьи.
Сначала создадим объект BeautifulSoup, передав в него текст статьи и указав парсер html.parser. Затем инициализируем два пустых списка: toc (для итогового оглавления) и stack (для временного хранения текущей структуры заголовков).
from bs4 import BeautifulSoup
from pytils.translit import slugify
def parse_article_content(content):
soup = BeautifulSoup(content, 'html.parser')
toc = []
stack = []
Теперь организуем цикл for, который пройдёт по всем заголовкам от <h2> до <h5> с использованием метода .find_all().
for header in soup.find_all(['h2', 'h3', 'h4', 'h5']):
Для каждого заголовка получим текст с помощью метода .get_text(strip=True) (он удаляет лишние пробелы и символы вроде \n). Затем извлечём id из заголовка, если он есть, или сгенерируем его с помощью функции slugify из библиотеки pytils. Этой теме я посвящал статью "Django 36. Добавление постов пользователем". После этого присвоим полученный id текущему тегу заголовка.
text = header.get_text(strip=True)
header_id = header.get('id') or slugify(text)
header['id'] = header_id
Следующим шагом определим уровень заголовка. Для этого извлечём второй символ из названия тега (h2, h3, и т.д.) и преобразуем его в число. Также создадим словарь node, описывающий текущий заголовок:
id— уникальный идентификатор заголовка для ссылок;text— текст заголовка;children— список дочерних элементов (заголовков более низкого уровня).
level = int(header.name[1])
node = {
'id': header_id,
'text': text,
'children': []
}
Далее организуем цикл while, который удаляет элементы из стека, пока уровень вложенности текущего заголовка меньше либо равен уровню последнего элемента в стеке.
while stack and stack[-1]['level'] >= level:
stack.pop()
После этого проверяем, есть ли элементы в стеке:
- Если есть, добавляем текущую ноду в список
childrenпоследнего элемента стека. - Если нет, помещаем текущую ноду в итоговый список
toc.
Затем добавляем текущий заголовок в стек.
if stack:
stack[-1]['node']['children'].append(node)
else:
toc.append(node)
stack.append({'node': node, 'level': level})
После завершения цикла возвращаем HTML-код с добавленными id и сформированный список оглавления toc.
Полный код функции
from bs4 import BeautifulSoup
from pytils.translit import slugify
def parse_article_content(content):
soup = BeautifulSoup(content, 'html.parser')
toc = []
stack = []
for header in soup.find_all(['h2', 'h3', 'h4', 'h5']):
text = header.get_text(strip=True)
header_id = header.get('id') or slugify(text)
header['id'] = header_id
level = int(header.name[1])
node = {
'id': header_id,
'text': text,
'children': []
}
while stack and stack[-1]['level'] >= level:
stack.pop()
if stack:
stack[-1]['node']['children'].append(node)
else:
toc.append(node)
stack.append({'node': node, 'level': level})
return str(soup), toc
Добавление оглавления в шаблон
Логика написана! Теперь нужно добавить отображение оглавления в шаблон. Это позволит пользователям быстро ориентироваться в содержимом статьи.
В этом блоке я опишу пример реализации, но имейте в виду, что внешний вид вашего сайта может потребовать адаптации кода.
Шаблон статьи
Перейдите в директорию с шаблонами и откройте файл post_page.html.
Найдите подходящее место для вставки кода — например, перед тегом {{ post.full_body | safe }}. Добавьте следующий код:
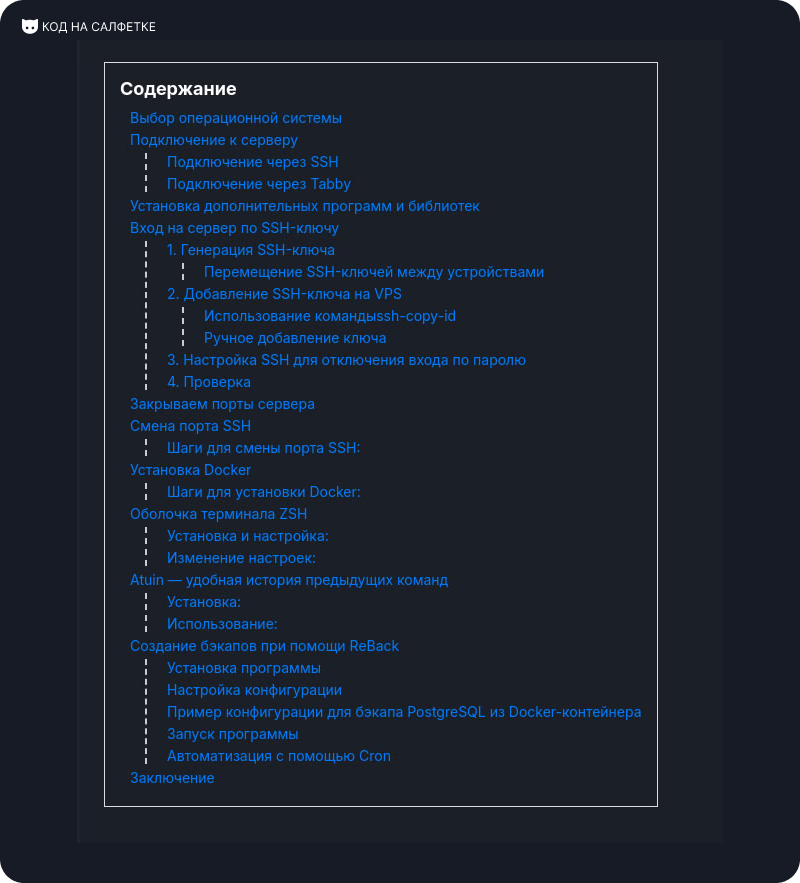
{% if post.table_of_contents %}
<div class="toc">
<h2>Содержание</h2>
<ul>
{% for item in post.table_of_contents %}
{% include "blog/modules/toc_item.html" with item=item %}
{% endfor %}
</ul>
</div>
{% endif %}
В этом коде:
Проверка на наличие оглавления: Используется условие {% if post.table_of_contents %}, чтобы убедиться, что у текущей статьи есть сгенерированное оглавление. Если оглавление отсутствует, блок не будет отображаться.
Цикл для вывода элементов оглавления: С помощью тега {% for item in post.table_of_contents %} мы перебираем элементы оглавления.
Включение шаблона элемента оглавления: Для каждого элемента вызывается отдельный шаблон toc_item.html, расположенный в директории modules. В этот шаблон передаётся текущий элемент оглавления через переменную item.
Модуль элемента оглавления
Для отображения элементов оглавления создадим отдельный шаблон. В директории modules создайте файл toc_item.html со следующим содержимым:
<li>
<a href="#{{ item.id }}">{{ item.text }}</a>
{% if item.children %}
<ul>
{% for child in item.children %}
{% include "blog/modules/toc_item.html" with item=child %}
{% endfor %}
</ul>
{% endif %}
</li>
Что происходит в этом шаблоне:
Ссылка на элемент оглавления: Используется тег <a>, который ссылается на соответствующий заголовок в статье по его id.
Рекурсивный вызов шаблона: Если у текущего элемента есть дочерние элементы (item.children), они выводятся внутри вложенного списка <ul>. Для каждого дочернего элемента снова используется этот же шаблон.
Вынос кода в отдельный файл позволяет удобно реализовать рекурсивное построение вложенных списков для многоуровневого оглавления.
Простейшие стили для оглавления
Добавим минимально необходимые стили, чтобы оглавление выглядело аккуратно. Откройте файл style.css в директории static и добавьте следующий код:
.toc {
border: 1px solid #ddd;
padding: 15px;
margin-bottom: 20px;
background-color: #f9f9f9;
}
.toc h2 {
font-size: 18px;
margin-bottom: 10px;
font-weight: bold;
}
.toc ul {
list-style: none;
padding-left: 0;
margin: 0;
}
.toc li {
margin: 5px 0;
padding-left: 10px;
}
.toc li a {
text-decoration: none;
color: #007bff;
font-size: 14px;
}
.toc li a:hover {
text-decoration: underline;
}
.toc ul ul {
margin-left: 15px;
border-left: 2px dashed #ccc;
padding-left: 10px;
}
Описание стилей:
- Блок оглавления (
.toc): Обрамляется тонкой границей, добавляется внутренний отступ (padding) и фон, чтобы выделить блок. - Заголовок (
.toc h2): Устанавливается размер шрифта, отступы и жирное начертание. - Списки (
.toc ul,.toc ul ul): Отключается стандартная маркеровка списков, а для вложенных списков добавляется визуальное выделение с помощью пунктирной линии. - Элементы списка (
.toc li) и ссылки (.toc li a): Задаются минимальные отступы и стили ссылок, чтобы сделать их более заметными.
Кнопка "Вернуться наверх"
Для того, чтобы пользователи могли быстро вернуться к оглавлению на длинных статьях, давайте добавим кнопку "Наверх", которая будет появляться при прокрутке страницы вниз и позволять быстро вернуться к началу.
Шаг 1: Создание JavaScript-файла
В директории static/js создадим новый файл up_button.js. В этом файле будем прописывать логику для двух событий.
Обработчик прокрутки
Первое событие будет обрабатывать прокрутку страницы. Как только пользователь прокрутит страницу вниз на 300 пикселей, кнопка с id "back-to-top" станет видимой. Если прокрутка будет меньше 300 пикселей, кнопка скрывается.
Пример кода для отслеживания прокрутки:
window.addEventListener('scroll', function () {
const button = document.getElementById('back-to-top');
if (window.scrollY > 300) {
button.style.display = 'block';
} else {
button.style.display = 'none';
}
});
Обработчик клика
Второе событие будет реагировать на клик по кнопке. Когда пользователь нажимает на кнопку, происходит плавная прокрутка страницы наверх. Для этого используется метод window.scrollTo() с параметром behavior: 'smooth', чтобы анимация прокрутки была плавной.
Пример кода для клика по кнопке:
document.getElementById('back-to-top').addEventListener('click', function () {
window.scrollTo({
top: 0,
behavior: 'smooth'
});
});
Шаг 2: Добавление кнопки в шаблон
Теперь нам нужно добавить саму кнопку в шаблон. Откроем файл post_page.html и вставим кнопку в любое место, где она будет находиться на странице. Поскольку кнопка будет скрыта по умолчанию с помощью стилей, можно поместить её в любое место.
Пример кнопки:
<button id="back-to-top" class="back-to-top">⬆️ Наверх</button>
Шаг 3: Подключение JavaScript-файла
Внизу страницы, перед закрытием блока {% endblock %}, добавим подключение только что созданного JavaScript-файла. Это нужно для того, чтобы подключить обработчики событий.
Пример подключения скрипта:
<script src="{% static "js/up_button.js" %}"></script>
Шаг 4: Стилизация кнопки
Теперь давайте добавим стили для кнопки. Откроем файл style.css и добавим следующее описание для кнопки "Наверх":
.back-to-top {
position: fixed; /* Кнопка фиксируется внизу справа */
bottom: 20px; /* Отступ от нижнего края */
right: 20px; /* Отступ от правого края */
padding: 10px 15px; /* Отступы внутри кнопки */
font-size: 16px; /* Размер текста на кнопке */
background-color: #007bff; /* Цвет фона кнопки */
color: white; /* Цвет текста на кнопке */
border: none; /* Без рамки */
border-radius: 5px; /* Скругление углов кнопки */
cursor: pointer; /* Курсор-указатель при наведении */
display: none; /* Изначально кнопка скрыта */
box-shadow: 0px 4px 6px rgba(0, 0, 0, 0.1); /* Тень для кнопки */
transition: opacity 0.3s; /* Плавное изменение видимости */
}
.back-to-top:hover {
background-color: #0056b3; /* Цвет кнопки при наведении */
}
Что делают эти стили:
- Позиционирование: Кнопка фиксируется внизу справа экрана и остаётся там даже при прокрутке страницы. Отступы от нижнего и правого краёв задаются в 20 пикселей.
- Визуальные эффекты: Внешний вид кнопки задаётся с фоном в цвет #007bff (голубой), белым текстом и скругленными углами. Кнопка будет с тенью для лучшего визуального восприятия.
- Скрытие: Кнопка изначально скрыта через
display: none;, и будет показана только при прокрутке страницы более чем на 300 пикселей. - Плавный переход: Свойство
transitionделает плавным изменение прозрачности кнопки, чтобы она не появлялась или исчезала резко.
Теперь кнопка "Наверх" будет показываться при прокрутке страницы более чем на 300 пикселей вниз. При клике на неё страница плавно прокрутится к началу.
Кнопки "Поделиться в социальных сетях"
Когда я решил добавить кнопки "Поделиться в социальных сетях" на сайт, я первым делом начал искать готовые решения для Django, но быстро понял, что актуальных решений не так много. Многие из них устарели и ориентированы на зарубежную аудиторию. В итоге я решил воспользоваться решением от Яндекса — Блок «Поделиться».
Шаг 1: Настройка в конфигураторе Яндекса
Для начала нужно настроить кнопки через конфигуратор Яндекса. Переходим по ссылке:
Конфигуратор Яндекс-Блока "Поделиться"
В конфигураторе можно выбрать, какие социальные сети будут отображаться, а также настроить вид и размер иконок.
После настройки, конфигуратор сгенерирует код, который будет выглядеть примерно так:
<script src="https://yastatic.net/share2/share.js"></script>
<div class="ya-share2" data-curtain data-shape="round" data-services="messenger,vkontakte,odnoklassniki,telegram,twitter,whatsapp,skype"></div>
Но мы немного его адаптируем под наш проект.
Шаг 2: Подключение скрипта
Для того чтобы кнопки работали на сайте, нам нужно подключить скрипт Яндекса. Откроем файл post_page.html и в самом конце, перед закрывающимся блоком {% endblock %}, добавим следующий код для подключения скрипта:
<script src="https://yastatic.net/share2/share.js" async></script>
Шаг 3: Добавление блока кнопок
Теперь давайте вставим сам блок кнопок в шаблон. Обычно такие кнопки удобно располагать в конце статьи, чтобы пользователи могли поделиться материалом после прочтения. Вставим следующий HTML код:
<div>
<h2>Поделиться:</h2>
<div class="ya-share2" data-curtain data-shape="round"
data-services="messenger,vkontakte,odnoklassniki,telegram,twitter,whatsapp,skype,linkedin"></div>
</div>Этот блок создаст кнопки для различных социальных сетей. Замените значения атрибута data-services на те, которые вы выбрали в конфигураторе Яндекса.
Шаг 4: Готово!
Теперь кнопки для поделиться в социальных сетях будут отображаться на странице, и пользователи смогут быстро поделиться статьёй в различных популярных мессенджерах и соцсетях.
Как видите, добавление кнопок с помощью решения от Яндекса очень простое и быстрое.
Заключение
Добавление кнопок "Поделиться" или кнопки "Вернуться наверх" оказалось довольно простым, и таких решений можно найти много в интернете. Можно считать это как "бонус" к основному описанию процесса добавления оглавления. В целом, процесс создания оглавления тоже был достаточно простым, хоть и немного объёмным.
Само оглавление на сайте оказалось действительно полезным. Оно не только позволяет быстро перейти к нужному разделу, но и благодаря идентификаторам заголовков позволяет встраивать ссылки на конкретные блоки в других статьях, а не просто ссылаться на всю статью целиком. Это значительно улучшает навигацию и помогает сделать контент более структурированным и удобным для пользователей.

Комментарии