
Если спросить у питониста: «Чем парсить сайт?», — в большинстве случаев он ответит Selenium или Beautiful Soup. И будет по-своему прав — это два главных направления в мире парсинга на Python.
Selenium, со всем своим множеством форков, наследников и схожих по принципу библиотек, — инструмент мощный. Он отлично подходит для сложных сценариев, работы с динамическими сайтами и автоматизации действий пользователя в браузере. Но за это удобство приходится платить: Selenium требует немало системных ресурсов и работает заметно медленнее.
Beautiful Soup (или просто «суп») — полная противоположность. Он лёгкий, быстрый и прекрасно справляется с «простыми» сайтами, где нет интерактивных элементов и сложного JavaScript.
В этой статье я расскажу об альтернативе Beautiful Soup — библиотеке Selectolax, воплощающую в себе простоту использования и высокую скорость работы.
Что такое ваш парсинг?
Небольшое лирическое отступление — для полноты картины.
Парсинг — это процесс извлечения нужной информации из какого-либо источника. И не обязательно это связано с сайтами — под парсингом можно понимать почти любую работу с данными, где нужно что-то найти, разобрать и выделить.
Примеры парсинга:
- поиск и получение информации с сайта;
- извлечение данных из файлов (например, CSV или логов);
- выделение нужных фрагментов из неструктурированного текста.
Что за.. Selectolax?
Selectolax — это высокопроизводительная библиотека для парсинга HTML, написанная на Python, но с использованием быстрых, низкоуровневых компонентов на C — Modest и Lexbor.
Если сказать проще, Selectolax сочетает удобство Python с производительностью, близкой к нативному коду. Благодаря этому она обрабатывает HTML-страницы в десятки раз быстрее, чем классические библиотеки вроде Beautiful Soup.
Главное преимущество Selectolax — она умеет работать с реальным, “грязным” HTML. Тем самым, что мы видим в браузере, а не в идеальных учебных примерах.
Для сравнения:
- В “супе” (
html.parser) весь разбор происходит на чистом Python — медленно, но надёжно. lxml, хоть и быстрее, изначально создавался для XML, а HTML поддерживает как бы “заодно”. Из-за этого он иногда “спотыкается” на современных HTML5-страницах.- Selectolax же использует специально оптимизированный парсер на C, изначально рассчитанный именно на HTML.
Чтобы было понятнее, вот упрощённая схема, как всё устроено “под капотом”:
# Под капотом Selectolax:
HTMLParser(html)
↓
Нативный C-парсер (Lexbor/Modest)
↓
Дерево в памяти на C
↓
Тонкая Python-прослойка для доступаА вот как работает Beautiful Soup:
# Под капотом BeautifulSoup:
BeautifulSoup(html, 'lxml') # или html.parser, или html5lib
↓
Внешний парсер (отдельная библиотека)
↓
Python-объекты (Tag, NavigableString)
↓
Дерево в памяти на чистом PythonИменно поэтому Selectolax не только быстрее, но и устойчивее к “грязным” или некорректным HTML-документам, которые на практике встречаются куда чаще, чем идеальные страницы из учебников.
Чистый и Грязный HTML?
Понятие "чистоты" условное, а не что-то из официальной терминологии.
К чистому HTML относят:
- Имеет валидную структуру (например, проходит проверку W3C Validator).
- Все теги закрыты, не нарушена вложенность и другие мелочи.
- Имеет логичную разметку в виде специализированных тегов.
К "грязному" HTML относится всё, что не попадает под понятия "чистого". Он может содержать незакрытые теги или некорректную вложенность, которую браузерный движок, в большинстве случаев, просто "адаптирует", но парсеры вроде Beautiful Soup наверняка споткнутся и упадут.
Установка и пример использования
Selectolax устанавливается просто и быстро — как любая другая библиотека Python:
# Если используется pip
pip install selectolax
# Если используется uv
uv add selectolax
# Если используется Poetry
poetry add selectolaxТеперь посмотрим на базовый пример использования:
from selectolax.parser import HTMLParser
html = """
<html>
<head><title>Пример страницы</title></head>
<body>
<div class="products">
<h1>Товары</h1>
<div class="product">
<span class="name">Телефон</span>
<span class="price">100$</span>
</div>
<div class="product">
<span class="name">Ноутбук</span>
<span class="price">500$</span>
</div>
</div>
</body>
</html>
"""
tree = HTMLParser(html=html)
products = tree.css('.product')
for product in products:
name = product.css_first('.name')
price = product.css_first('.price')
print(f"Товар: {name.text()}, Цена: {price.text()}")Результат:
Товар: Телефон, Цена: 100$
Товар: Ноутбук, Цена: 500$Разбор примера
- Переменная
html— это просто текст страницы.
В реальной задаче сюда обычно подставляют результат запроса (например, черезhttpxилиaiohttp), но для демонстрации проще использовать статичный HTML. HTMLParser(html=html)создаёт объектtree, который представляет собой разобранную HTML-страницу.
По сути, это DOM-дерево, с которым можно работать привычными методами: искать элементы, обходить их, доставать текст и атрибуты.tree.css('.product')возвращает список всех элементов с классомproduct.
Методы.css()и.css_first()позволяют использовать CSS-селекторы — то же самое, что и в браузере, поэтому работать с ними интуитивно просто.- Дальше мы просто проходимся по найденным блокам и для каждого достаём:
.css_first('.name')— первый элемент с классомname;.css_first('.price')— первый элемент с классомprice;.text()— текстовое содержимое элемента.
После этого выводим результат в консоль.
Хватит теории, переходим к практике!
“Буквы, буквы, буквы… А где реальные примеры?” — есть у меня такие!
В качестве “тестового полигона” возьмём Habr.
Попробуем спарсить страницу со статьями: https://habr.com/ru/articles/!
Важно: в этой статье мы не будем обсуждать архитектуру проекта или организацию кода.
Для наглядности всё будет написано в одном файле —main.py.
Но в реальных проектах, конечно, не забывайте разбивать код на модули и держать структуру аккуратной.
Поиск селекторов
Прежде чем начинать парсить страницу, нужно понять, где именно находятся нужные данные.
Для этого открываем страницу в браузере и ищем подходящие селекторы — классы, блоки или XPath-пути, по которым потом будем обращаться к элементам.
Откроем сайт и нажмём F12, чтобы вызвать инструменты разработчика (DevTools):
В левом верхнем углу панели инструментов есть кнопка в виде курсора (или используем горячие клавиши Ctrl + Shift + C).
С её помощью можно навести мышкой на любой элемент страницы и сразу увидеть его HTML-разметку.
Элемент статьи
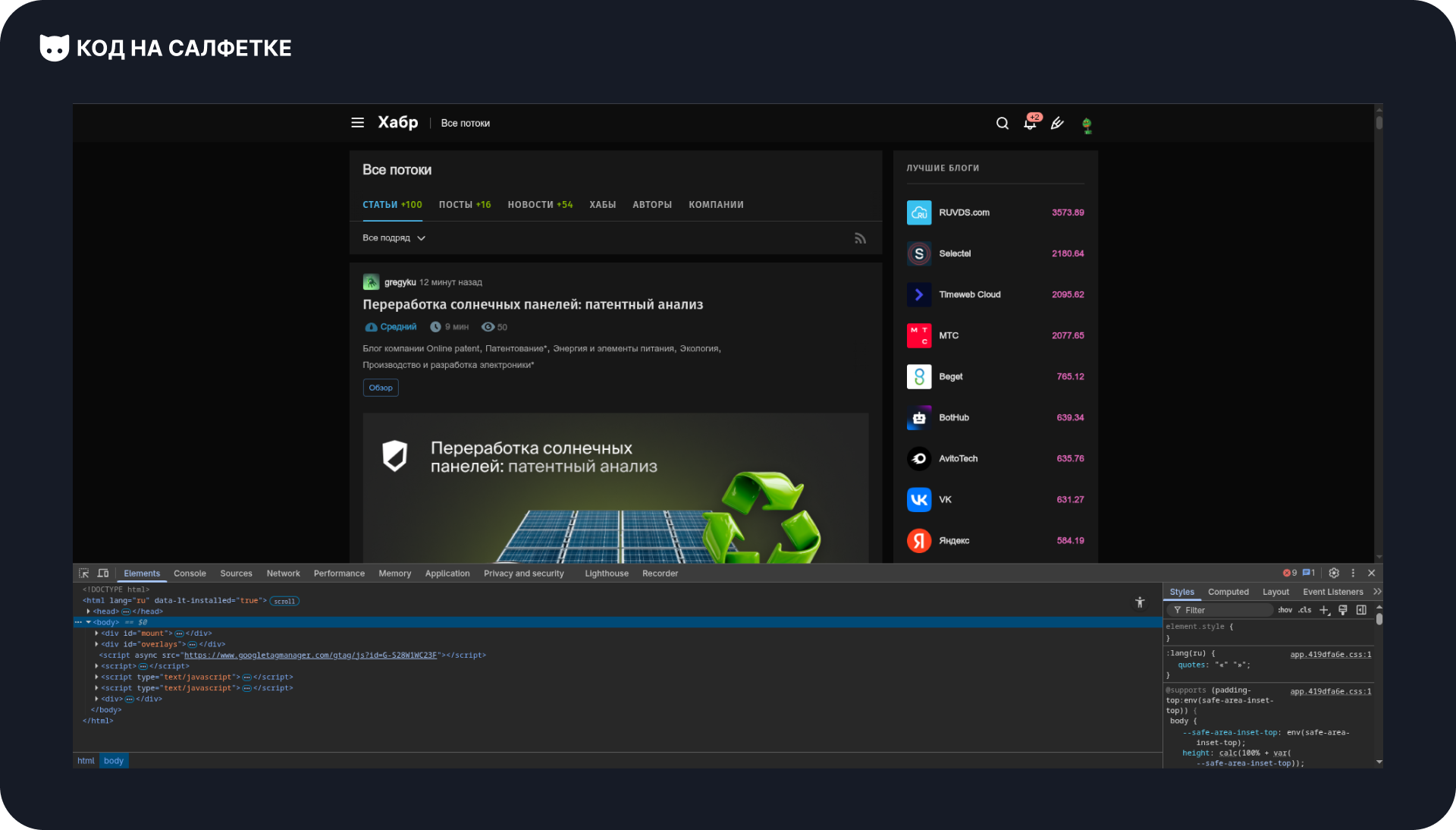
Начнём с выбора первого элемента статьи:
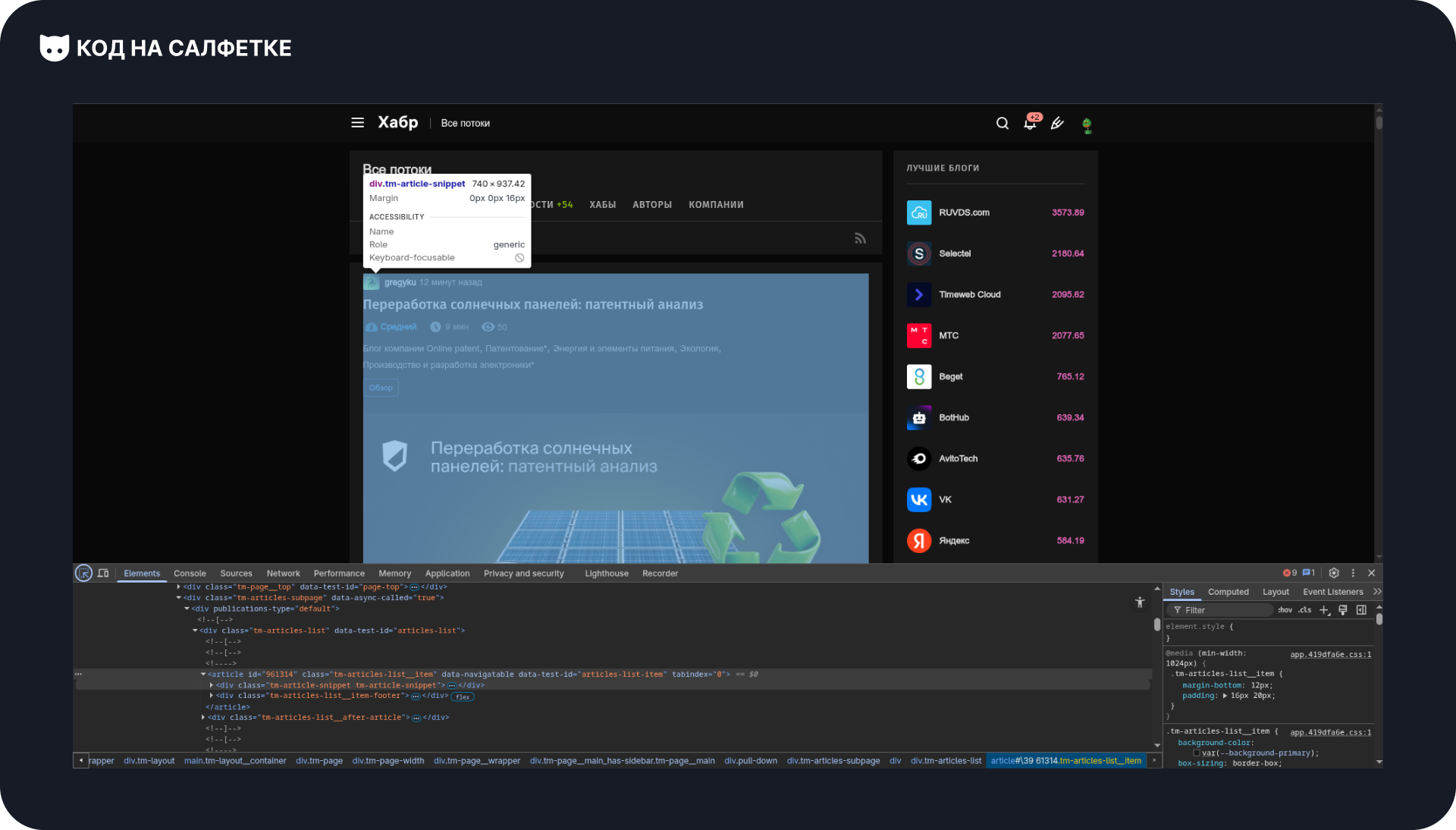
Мы видим блок с классами: tm-article-snippet tm-article-snippet.
Да, у него два класса. В HTML классы разделяются пробелом, а в CSS — наоборот, точкой, если нужно указать несколько сразу.
Например: .Itm-article-snippet.tm-article-snippet.
Такой селектор выберет элементы, у которых есть оба класса одновременно.
Важно помнить:
- точка в начале (
.) указывает, что это CSS-класс, а не тег; - если классов несколько — пробел между ними заменяем на точку.
Таким образом, селектор для нашего элемента статьи выглядит так: .tm-article-snippet.tm-article-snippet.
Однако, сам блок статьи состоит из нескольких вложенных элементов.
Для примера нам понадобятся:
- Имя автора и ссылка на его профиль.
- Название статьи и ссылка на полную версию.
- Краткое описание статьи.
Находим имя пользователя:
Выделяем элемент с именем пользователя и выделяется его элемент:
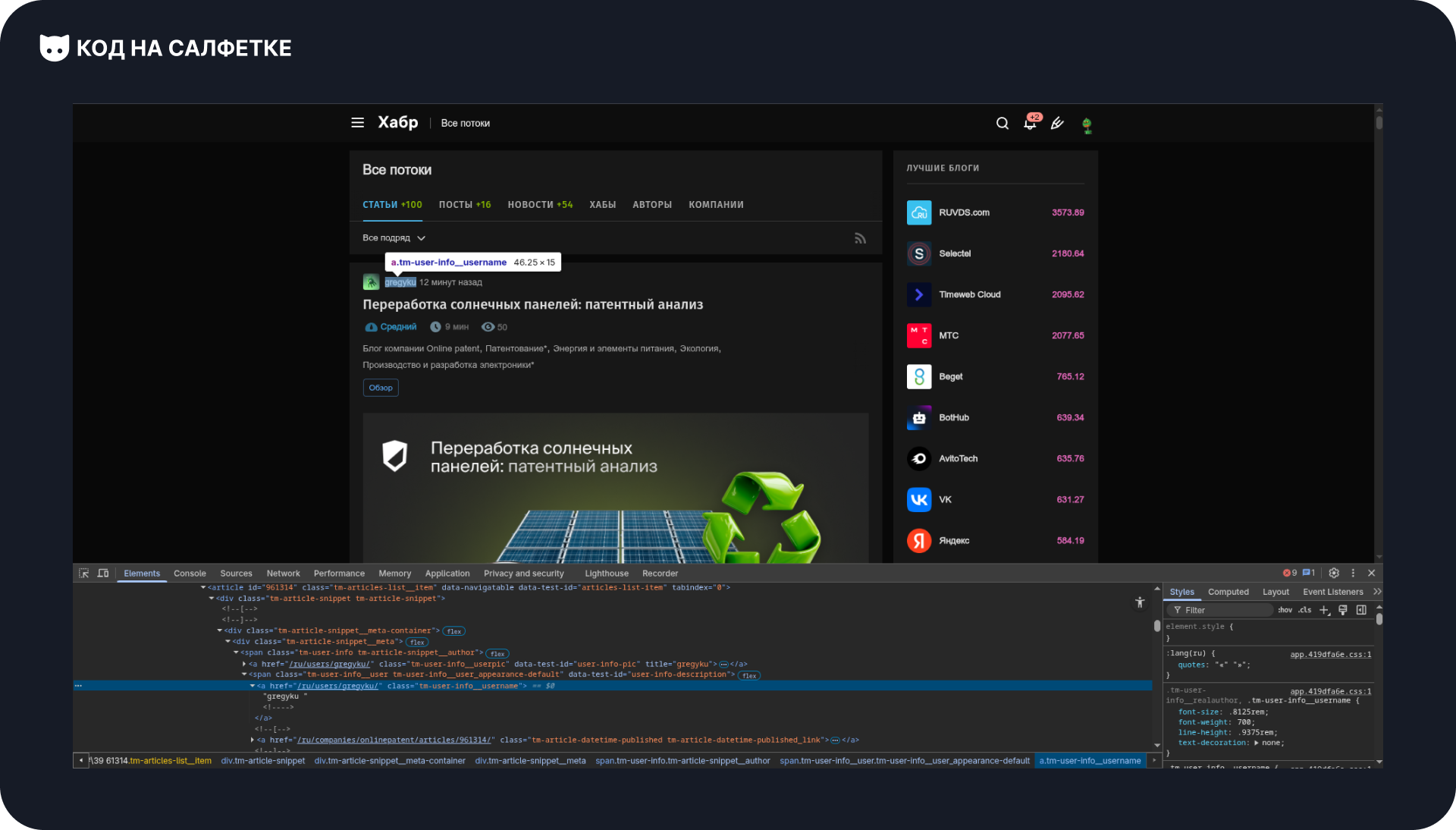
Запоминаем класс элемента: .tm-user-info__username.
Далее — заголовок статьи:
Выделяем и находим его элемент:
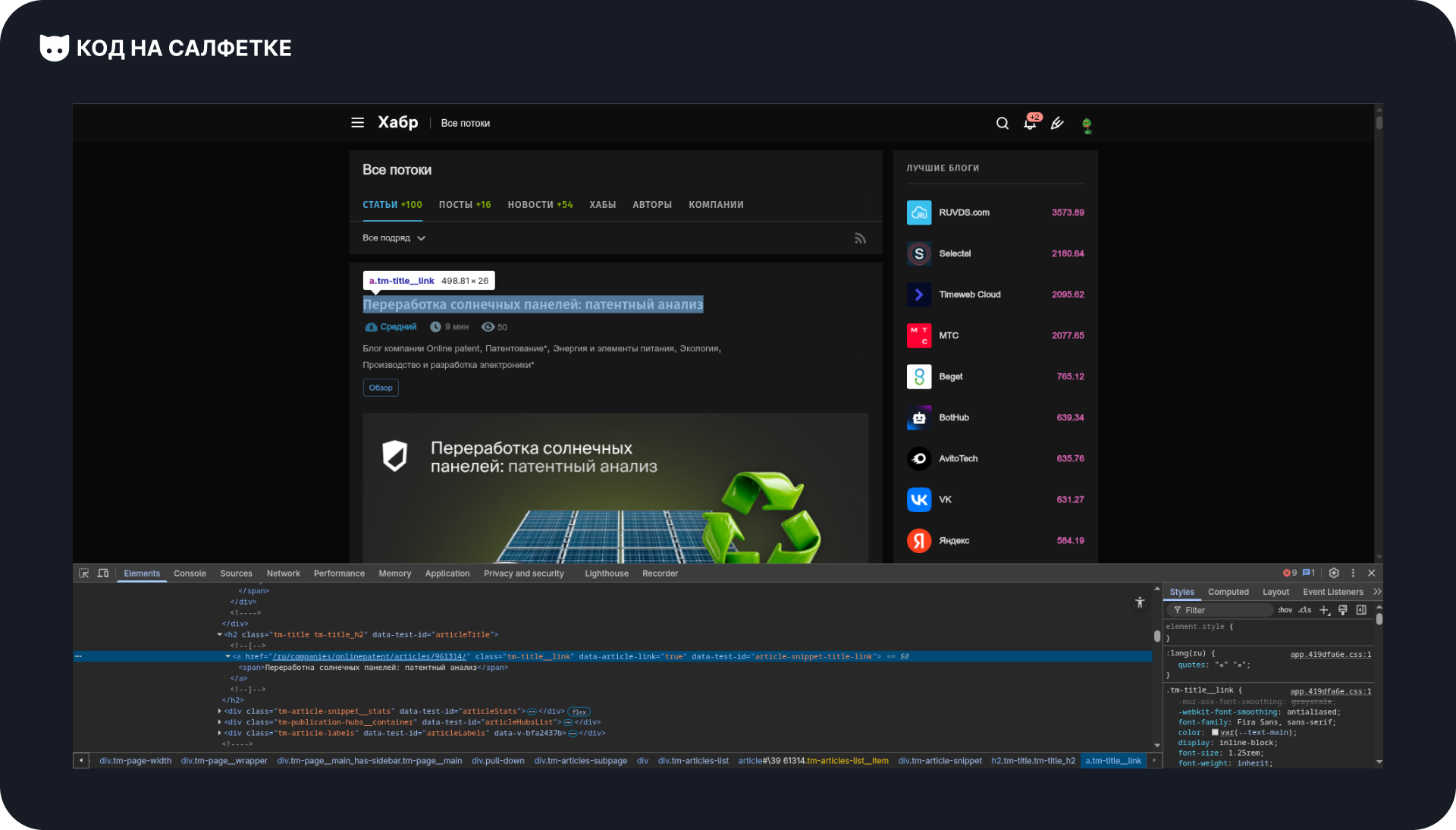
Запоминаем его класс: .tm-title__link
И наконец — краткое описание статьи:
Выделяем его и находим:
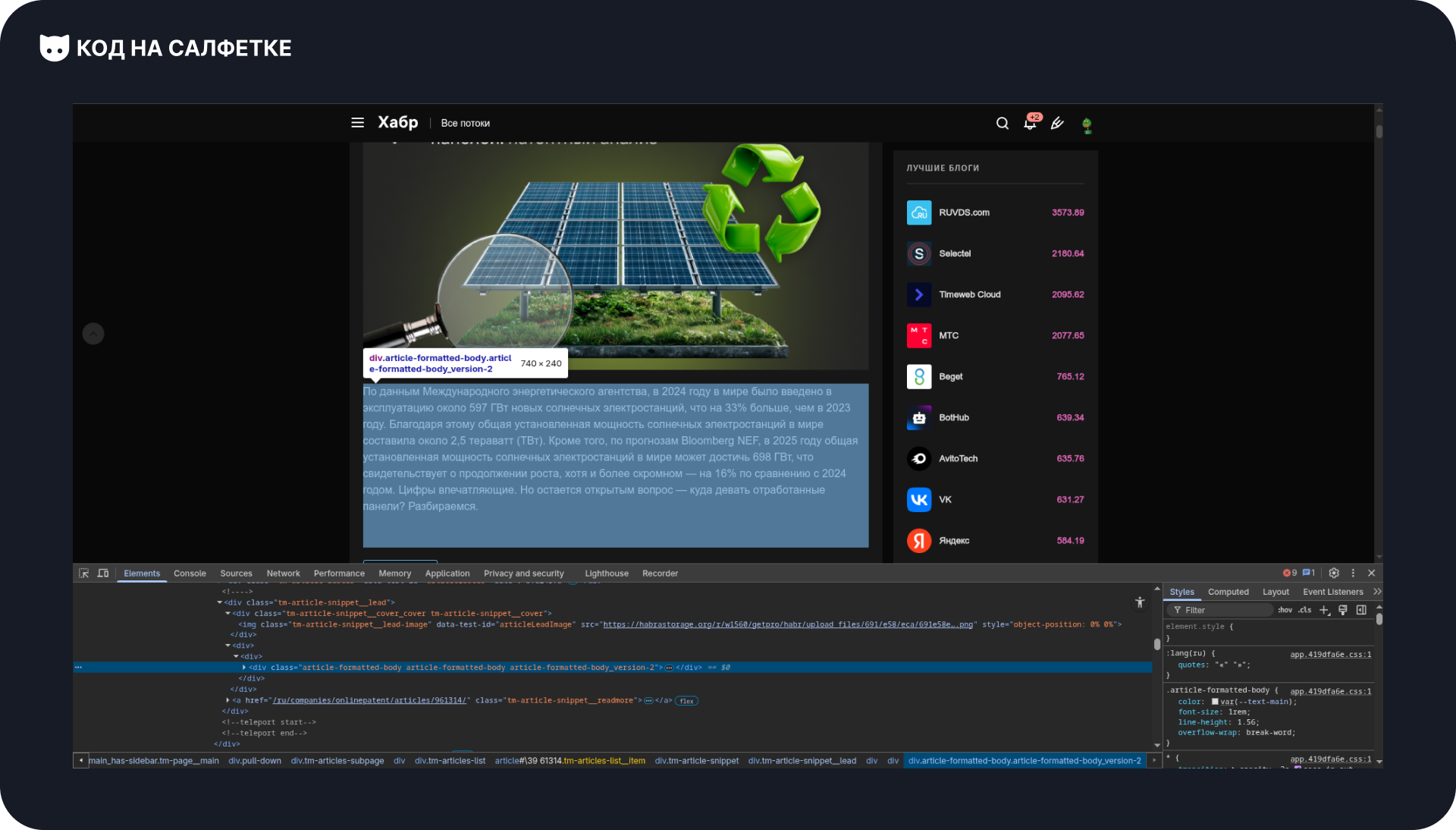
Здесь у элемента три класса.
Как и раньше, соединяем их точками, чтобы указать, что все они принадлежат одному элементу: article-formatted-body.article-formatted-body.article-formatted-body_version-2.
Элемент списка статей
Иногда элементы с одинаковым классом встречаются в разных частях страницы.
Например, блок .tm-article-snippet может быть не только в основном списке статей, но и в других частях страницы.
Чтобы не получить лишние результаты, нужно сузить область поиска — указать, в каком именно месте страницы мы хотим искать статьи.
Как это сделать:
- В инструментах разработчика (DevTools) выделяем найденный элемент статьи.
- Затем с помощью стрелок поднимаемся “вверх” по дереву элементов, пока не окажется выделена вся секция, где находятся наши статьи.
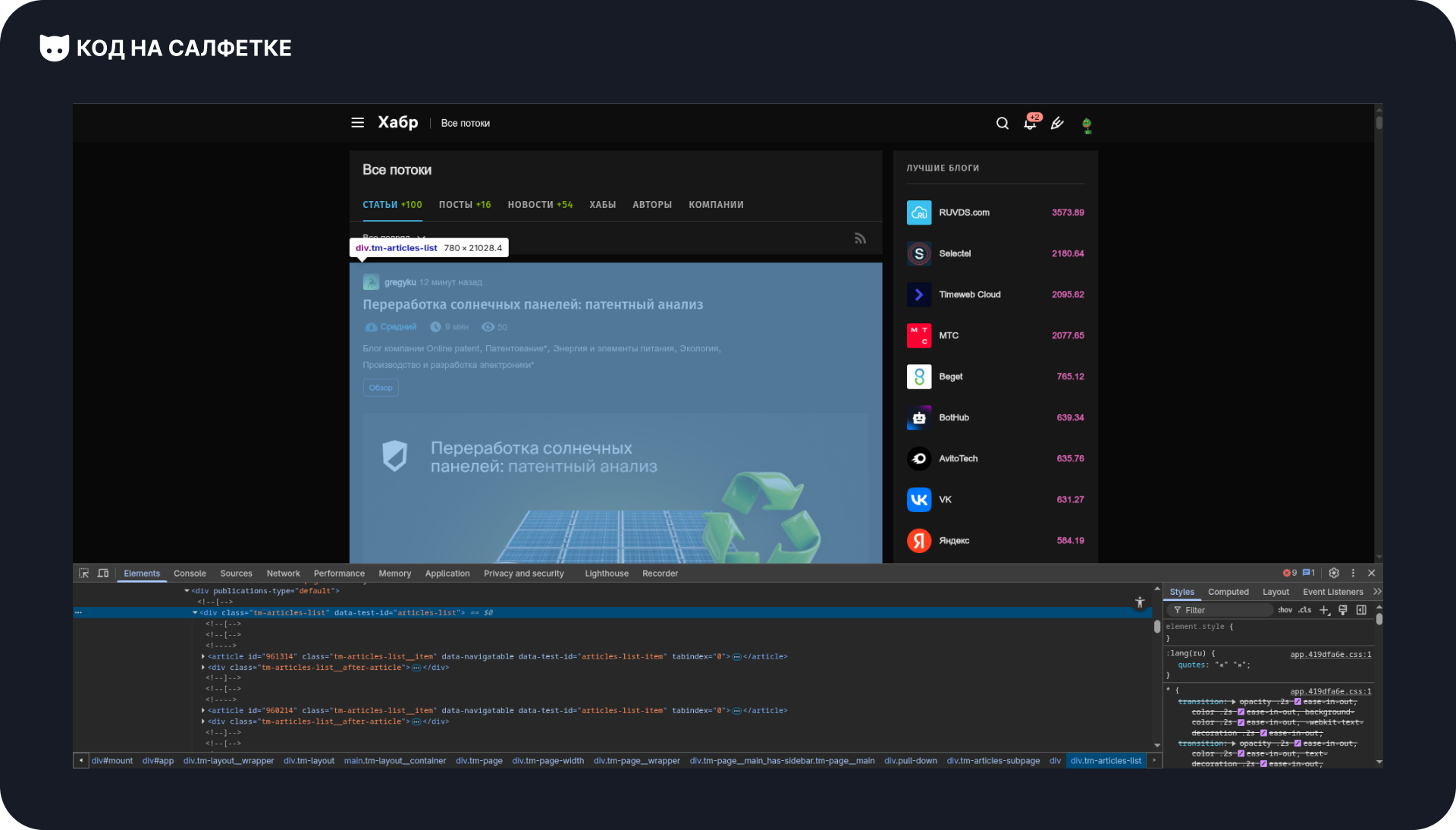
Находим класс: .tm-articles-list.
Запоминаем его — он пригодится нам в коде, чтобы ограничить поиск только нужной областью.
Теперь можно переходить в IDE и пробовать работать с ним в Selectolax!
Окружение
Перед тем как писать код, нужно подготовить рабочее окружение — создать виртуальное окружение и установить нужные библиотеки.
Это делается буквально в пару команд:
# Создаём виртуальное окружение
python -m venv .venv
# Активация в Windows
.venv\Scripts\activate
# Активация в Linux/MacOS
source .venv/bin/activateПосле активации окружения можно установить зависимости.
Помимо Selectolax, нам понадобится библиотека HTTPX — она отвечает за отправку HTTP-запросов и получение страниц:
pip install selectolax httpxГотово!
Теперь у нас есть всё необходимое, чтобы приступить к написанию кода и начать парсить страницы.
Код парсера
Создадим и откроем файл main.py.
Для начала определим основные константы, которые помогут сделать код аккуратнее и понятнее:
URL— страница, с которой будем парсить статьи.ARTICLES_LIST- селектор блока, где находятся все статьи.ARTICLE_ELEMENT- селектор отдельного блока статьи.POST_AUTHOR_ELEMENT- селектор элемента с именем автора.POST_LINK_ELEMENT- селектор элемента с названием и ссылкой статьи.POST_SNIPPET_ELEMENT- селектор блока с кратким описанием статьи.
URL = "https://habr.com/ru/articles/"
ARTICLES_LIST = ".tm-page__main_has-sidebar.tm-page__main"
ARTICLE_ELEMENT = ".tm-article-snippet.tm-article-snippet"
POST_AUTHOR_ELEMENT = ".tm-user-info__username"
POST_LINK_ELEMENT = ".tm-title__link"
POST_SNIPPET_ELEMENT = ".article-formatted-body.article-formatted-body.article-formatted-body_version-2"Теперь создадим функцию parse_articles() — она будет отвечать за получение и обработку данных.
В начале функции объявим пустой словарь articles, в который будем складывать найденные статьи:
def parse_articles() -> dict[int, dict[str, str]]:
articles = {}Получаем страницу.
Далее нужно загрузить HTML страницы.
Если вы работаете в синхронном коде, используйте Client() из библиотеки httpx.
Когда проект асинхронный — можно заменить его на AsyncClient().
response = Client().get(url=URL)Теперь создаём объект парсера:
tree = HTMLParser(html=response.text)HTMLParser превращает полученный HTML-код в удобное дерево элементов (DOM), с которым мы можем работать через CSS-селекторы.
Ищем список статей.
На странице все статьи находятся внутри определённого контейнера.
Чтобы его найти, используем метод .css_first(), который возвращает первый элемент, подходящий под указанный селектор:
articles_list = tree.css_first(ARTICLES_LIST)После этого у нас есть элемент, внутри которого лежат все карточки статей.
Проходимся по всем статьям.
Теперь нужно найти каждую статью внутри articles_list.
Для этого вызываем метод .css() и передаём ему селектор ARTICLE_ELEMENT.
Чтобы в дальнейшем удобно сохранять результаты, оборачиваем цикл в enumerate — так у каждой статьи будет порядковый номер:
for num, article in enumerate(articles_list.css(ARTICLE_ELEMENT), start=1):Извлекаем данные.
Внутри цикла достаём нужные элементы: автора, заголовок, ссылку и краткое описание.
Используем методы .css_first() для поиска, .text() для получения текста и .attributes.get() — для доступа к атрибутам (в нашем примере, href).
author = article.css_first(POST_AUTHOR_ELEMENT)
author_name = author.text()
author_link = author.attributes.get("href")
post = article.css_first(POST_LINK_ELEMENT)
post_title = post.text()
post_link = post.attributes.get("href")
post_snippet = article.css_first(POST_SNIPPET_ELEMENT).text()Сохраняем результат.
Добавляем полученные данные в словарь articles, где ключом будет номер статьи:
articles[num] = {
"author": author_name,
"author_link": author_link,
"post_title": post_title,
"post_link": post_link,
"post_snippet": post_snippet,
}Финальный шаг.
После завершения цикла возвращаем итоговый словарь articles:
return articlesТеперь наша функция полностью готова.
Она получает страницу, разбирает её, извлекает нужные данные и возвращает их в виде аккуратной структуры, готовой для дальнейшей обработки — например, вывода в консоль, сохранения в JSON или записи в базу.
Запуск
В конце файла добавим точку входа:
if __name__ "__main__":
pprint(parse_articles())Функция pprint выведет данные в удобочитаемом формате.
Запускаем скрипт — в терминале появляется список статей:
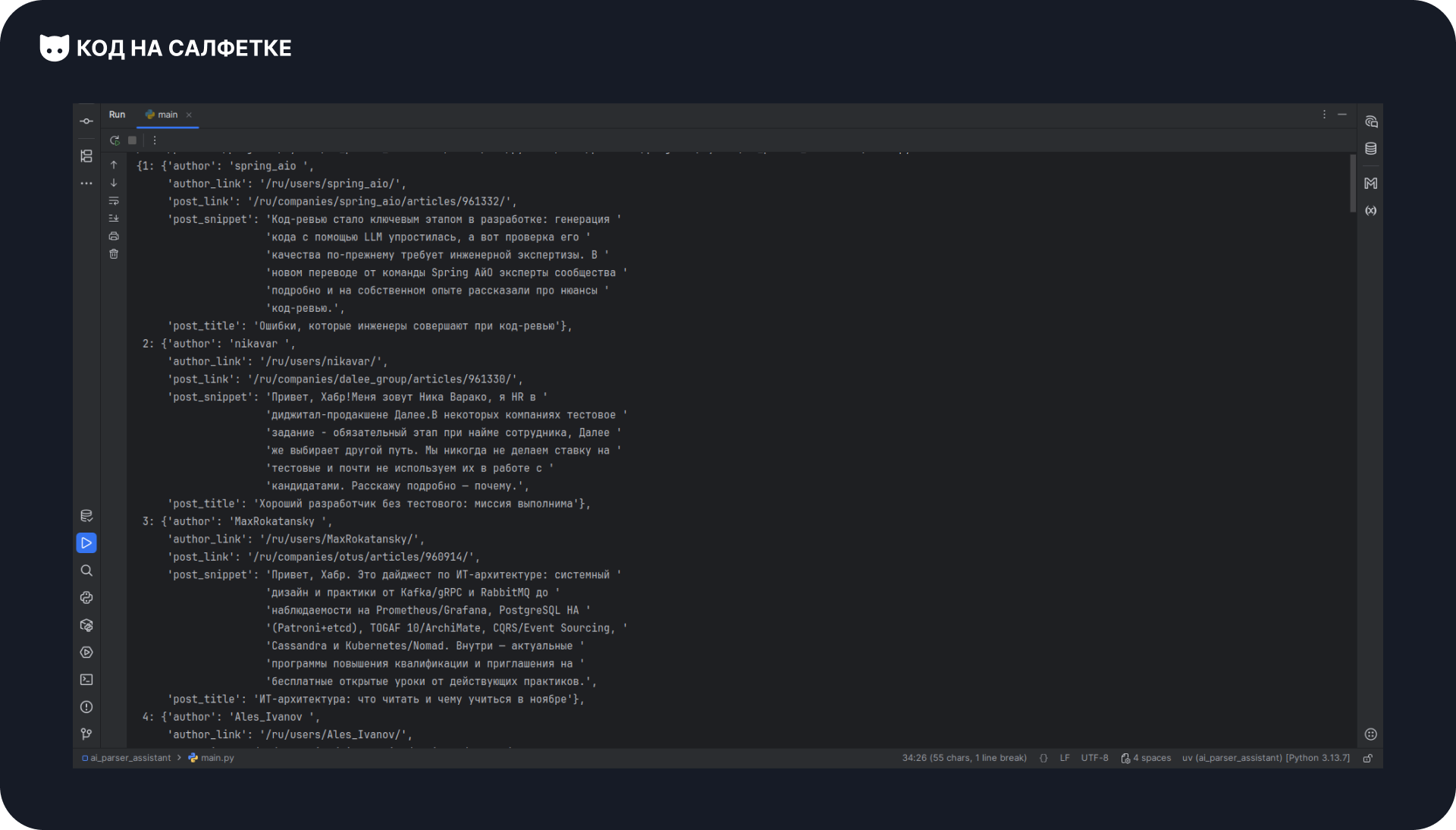
Полный код
from pprint import pprint
from httpx import Client
from selectolax.parser import HTMLParser
URL = "https://habr.com/ru/articles/"
ARTICLES_LIST = ".tm-page__main_has-sidebar.tm-page__main"
ARTICLE_ELEMENT = ".tm-article-snippet.tm-article-snippet"
POST_AUTHOR_ELEMENT = ".tm-user-info__username"
POST_LINK_ELEMENT = ".tm-title__link"
POST_SNIPPET_ELEMENT = ".article-formatted-body.article-formatted-body.article-formatted-body_version-2"
def parse_articles() -> dict[int, dict[str, str]]:
articles = {}
response = Client().get(url=URL)
tree = HTMLParser(html=response.text)
articles_list = tree.css_first(ARTICLES_LIST)
for num, article in enumerate(articles_list.css(ARTICLE_ELEMENT), start=1):
author = article.css_first(POST_AUTHOR_ELEMENT)
author_name = author.text()
author_link = author.attributes.get("href")
post = article.css_first(POST_LINK_ELEMENT)
post_title = post.text()
post_link = post.attributes.get("href")
post_snippet = article.css_first(POST_SNIPPET_ELEMENT).text()
articles[num] = {
"author": author_name,
"author_link": author_link,
"post_title": post_title,
"post_link": post_link,
"post_snippet": post_snippet,
}
return articles
if __name__ "__main__":
pprint(parse_articles())Заключение
Парсинг — полезный навык в арсенале программиста. И речь не только о веб-страницах — понятие гораздо шире. Даже если вы просто принимаете CSV-файл и извлекаете из него данные, это тоже своего рода парсинг.
Важно помнить: собирать данные с чужих сайтов без разрешения — плохая идея и порой на грани законности. Делайте это только там, где это разрешено.

Комментарии