
Сегодня искусственным интеллектом уже никого не удивишь. Из "каждого утюга" звучат слова: "AI, AI, AI". Однако далеко не все могут внятно объяснить, для чего этот AI нужен. Для нас, разработчиков, взаимодействие с искусственным интеллектом чаще всего сводится к использованию языковых моделей (LLM, Large Language Models), таких как GPT (Generative Pre-trained Transformer).
Это могут быть продукты OpenAI, например ChatGPT, или разработки других компаний: Gemini от Google, Claude от Anthropic, YandexGPT от Яндекса (не путать с Алисой), GigaChat от СБЕР и другие. Выбор конкретной модели обычно определяется задачами и доступным бюджетом.
Чаще всего эти модели работают "где-то там" — на удалённых серверах, доступ к которым осуществляется через браузер или API. Другими словами, для работы с такими моделями всегда требуется интернет-соединение. Не стоит забывать о конфиденциальности: всё, что передаётся в такие сервисы, может быть обработано, сохранено и использовано компанией, предоставляющей доступ (а иногда даже утекать 😉).
Что же делать, если нужен "цифровой помощник", который работает оффлайн или интегрируется во внутреннюю корпоративную систему, исключая риск утечек данных? В таких случаях на помощь приходят квантованные модели — специально оптимизированные для работы в локальных средах.
Пример помощника, о котором сегодня пойдет речь:
Если вам интересны подобные материалы, подписывайтесь на Telegram-канал «Код на салфетке». Там я делюсь гайдами для новичков, полезными инструментами и практическими примерами из реальных проектов.
Дисклеймер
Я не являюсь специалистом в области машинного обучения (ML) или науки о данных (DS). То, что описано ниже, — это моя попытка разобраться, как всё устроено, и поделиться этим с вами. Если вы найдете неточности или ошибки в терминологии или описании, пожалуйста дайте об этом знать.
Перед началом обозначу используемое оборудование и окружение:
- CPU: AMD Ryzen 3600
- GPU: NVIDIA RTX 3060 Ti (8 ГБ)
- RAM: 32 ГБ DDR4 3200 МГц
- OS: GNU/Linux Debian 12
Всё описанное выполняется на GNU/Linux Debian 12. Однако, на Windows или macOS это также должно работать без значительных изменений.
Особенность для пользователей macOS: большинство инструментов оптимизировано для компьютеров с процессорами Apple M-серии. Если у вас устройство на базе Intel (включая хакинтош), некоторые шаги могут быть несовместимы или менее производительны.
Что такое квантизация моделей?
Квантизация моделей — это процесс оптимизации, при котором уменьшается точность представления числовых значений в модели машинного обучения.
Основная цель — сократить размер модели и ускорить её вычисления. В этом процессе вещественные числа (например, 32-битные или 64-битные) заменяются на целые числа меньшего разряда (например, 8-битные).
Дополнительную информацию можно найти в статье на Хабре.
Как работает квантизация?
- Выбор точности: Определяется степень уменьшения разрядности чисел (например, до 8 или 16 бит).
- Диапазон значений: Исходные веса модели распределяются по интервалам, каждый из которых сопоставляется определённому целому числу.
- Округление: Значения весов модели округляются до ближайших значений из сокращённого диапазона.
- Калибровка (опционально): Модель донастраивается на калибровочных данных для минимизации потерь точности.
Преимущества квантизации
- Уменьшение размера модели: Сокращение объёма данных упрощает хранение и передачу.
- Ускорение вычислений: Операции над числами меньшей разрядности выполняются быстрее, что ускоряет инференс (предсказание).
- Экономия ресурсов: Сокращение объёма памяти и потребляемой энергии делает модели пригодными для работы на устройствах с ограниченными ресурсами (например, смартфонах или IoT-устройствах).
Ограничения квантизации
- Потеря точности: Модель может хуже предсказывать результаты. Современные методы минимизируют эти потери, но они всё же могут быть ощутимы в некоторых случаях.
Основные виды квантизации
- Полная квантизация: Все веса модели представляются в сокращённом диапазоне (например, целыми числами).
- Пост-обучающая квантизация (PTQ): Разные слои модели квантизуются с учётом их важности, чтобы сбалансировать точность и производительность.
- Динамическая квантизация: Веса остаются в исходном формате, но входные данные и промежуточные результаты квантизуются во время инференса.
Типы квантизации и их свойства
| Тип | Бит на вес | Размер модели относительно оригинала | Примечания |
|---|---|---|---|
| Q2_0 | 2 | 1/8 | Минимальный размер, низкая точность. Используется для устройств с жёсткими ограничениями. |
| Q4_0 | 4 | 1/2 | Популярный компромисс между точностью и сжатием. |
| Q8_0 | 8 | 1 | Почти равен оригинальной модели по размеру, обеспечивает максимальную точность после квантизации. |
Специальные обозначения
- "0": Симметричное распределение значений вокруг нуля.
- "K", "M", "L": Обозначают уникальные параметры распределения весов, используемые в сложных вариантах квантизации (например, Q4_K_M или Q6_K_L).
Пример:
- Q4_0: Квантизация весов до 4 бит с симметричным распределением.
- Q6_K_L: Более сложный метод, где 6 бит используется для кодирования распределённых групп значений.
Где искать модели?
Информацию о существующих языковых моделях, их рейтингах и применении можно взять из множества источников: от Telegram-каналов, посвящённых искусственному интеллекту, до специализированных сайтов вроде Хабра, непосредственно модели доступны на LLM Explorer и Hugging Face.
LLM Explorer
LLM Explorer — это веб-приложение, созданное для анализа и исследования доступных крупных языковых моделей (LLMs).
Ключевые функции LLM Explorer:
- Обширный каталог моделей: Предоставляет детальную информацию о различных языковых моделях, включая их архитектуру, размер и ключевые особенности.
- Сравнение производительности: Позволяет анализировать модели по таким параметрам, как точность, скорость выполнения и количество параметров.
- Визуализация данных: Интерактивные графики и диаграммы облегчают восприятие характеристик моделей.
- Интеграция с Hugging Face: Данные из репозитория Hugging Face можно использовать напрямую для анализа и сравнения.
Hugging Face
Hugging Face — это универсальная платформа для машинного обучения и искусственного интеллекта, которая предлагает широкий спектр предобученных моделей, инструментов и библиотек.
Основные возможности Hugging Face:
- Репозиторий моделей: Более 25 тысяч моделей для задач обработки естественного языка (NLP), компьютерного зрения и других областей машинного обучения.
- Библиотека Transformers: Python-библиотека, которая упрощает разработку и обучение моделей. Поддерживает архитектуры вроде BERT, GPT, ViT и предоставляет готовые модели для множества задач.
- Spaces: Интерактивная платформа для развертывания приложений, демонстраций и анализа данных. Идеально подходит для создания визуальных интерфейсов на основе ML-моделей.
- Datasets библиотека: Широкий выбор наборов данных для обучения и тестирования, включая структурированные и неструктурированные данные.
- Продукты и сервисы:
- Inference API: Выполнение запросов к моделям через API без локальной установки.
- Инструменты для обучения моделей: Поддержка распределённого обучения на больших данных с использованием облачных ресурсов.
Как выбрать модель?
Выбор модели для машинного обучения зависит от задач, доступного оборудования и ограничений по ресурсам. В этом блоке мы попробуем разобраться, как определить подходящую модель, оценив ее потребности учитывая влияние размера и квантизации на использование памяти.
Ключевые аспекты выбора модели
- Цель использования Определите задачу: это может быть обработка текста, генерация изображений или решение конкретной проблемы, например, программирование. Задача определяет требования к модели, например:
- Нужна высокая точность для аналитики.
- Достаточно средней точности для чат-бота.
- Точность и размер
- Крупные модели обеспечивают высокую точность, но требуют значительных ресурсов.
- Меньшие модели подходят для устройств с ограниченными ресурсами, хотя их точность может быть ниже.
- Совместимость
Убедитесь, что модель поддерживает выбранные инструменты: TensorFlow, PyTorch, ONNX и др. Например, некоторые модели оптимизированы только под GPU от NVIDIA. - Ресурсные ограничения
Узнайте, сколько видеопамяти (GPU memory), оперативной памяти (RAM) и вычислительных мощностей потребуется. Эти параметры зависят от размера модели и формата квантизации.
Какие ресурсы требует модель?
При работе с моделью используются:
- Видеопамять (GPU memory)
- Хранение весов модели.
- Ускоренные вычисления на GPU.
- Запуск на устройствах с ограниченной видеопамятью может быть невозможен.
- Оперативная память (RAM)
- Используется для загрузки модели, обработки входных данных и хранения промежуточных результатов.
- Меньшие модели требуют меньше RAM, что полезно для серверов или мобильных устройств.
- Вычислительная мощность (CPU/GPU)
- Крупные модели могут занимать часы или дни на менее мощных устройствах.
Как размер модели влияет на ресурсы?
- Объём параметров
- Модели с миллиардами параметров требуют десятки гигабайт видеопамяти (например, 13B или 30B параметров).
- Модели меньшего размера (например, 7B) работают на потребительских видеокартах с 8–12 ГБ.
- Квантизация Преобразование весов модели в меньшие разряды (например, из 32-битных чисел в 8-битные) снижает нагрузку на память:
- Q4_0 (4 бита): экономит видеопамять вдвое по сравнению с 8-битной моделью.
- Q8_0 (8 бит): практически без потери точности, но меньше оптимизации.
Пример:
Модель GPT с параметрами 13B потребует:
- Около 13 ГБ видеопамяти в 8-битном представлении.
- Всего 6.5 ГБ видеопамяти в 4-битной квантованной версии.
Что происходит при нехватке памяти?
Видеопамять
Если GPU не может вместить модель:
- Работа перемещается на CPU, что сильно замедляет выполнение.
- Возможны ошибки загрузки модели.
Решения: - Использовать меньшие модели.
- Применить квантизацию (например, Q4_0 вместо Q8_0).
- Разделить модель на части для запуска на нескольких GPU.
Оперативная память
Нехватка RAM может привести к сбоям загрузки модели или длительным задержкам.
Решения:
- Убедитесь, что устройство имеет достаточную RAM.
- Используйте меньшие форматы данных или модели.
Рекомендации по выбору модели
- Оцените ресурсы Узнайте доступный объём видеопамяти и оперативной памяти.
- Для 8–12 ГБ GPU: используйте 7B модели с квантизацией (например, Q4_0).
- Для 16–24 ГБ GPU: подойдут 13B или даже 30B с более высокой точностью.
- Подберите подходящий формат
- Квантизация снижает ресурсные затраты.
- Используйте динамическую квантизацию для мобильных приложений.
- Тестируйте
Протестируйте модель на реальных задачах. Компромисс между точностью и ресурсами должен удовлетворять требованиям задачи.
Скачивание модели
После выбора модели, совместимой с вашим оборудованием, необходимо скачать её GGUF-версию — формат квантированных моделей. Этот формат уменьшает размер модели и снижает требования к ресурсам.
Самый популярный ресурс для скачивания моделей — это Hugging Face.
Открываем сайт и вводим в поиск название нужной модели, например: Qwen/Qwen2.5-Coder-7B-Instruct-GGUF.
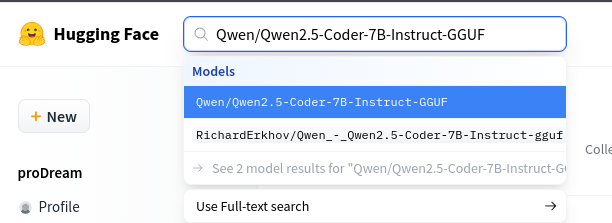
На странице модели обратите внимание на правый блок с разделом GGUF:
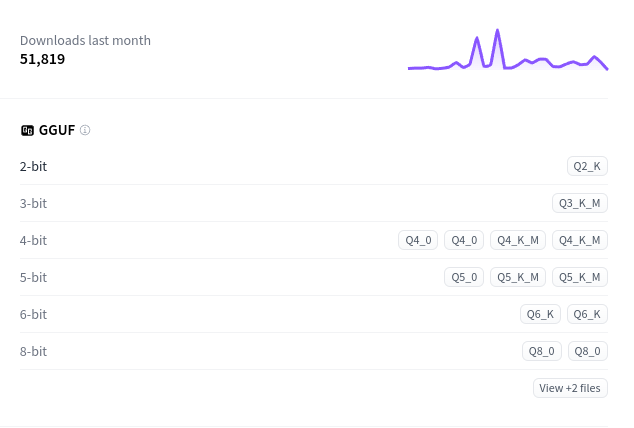
В нём перечислены доступные форматы, такие как Q4_0, Q5_0, и другие. Выбираем нужный формат (например, Q4_0) и нажимаем на него.
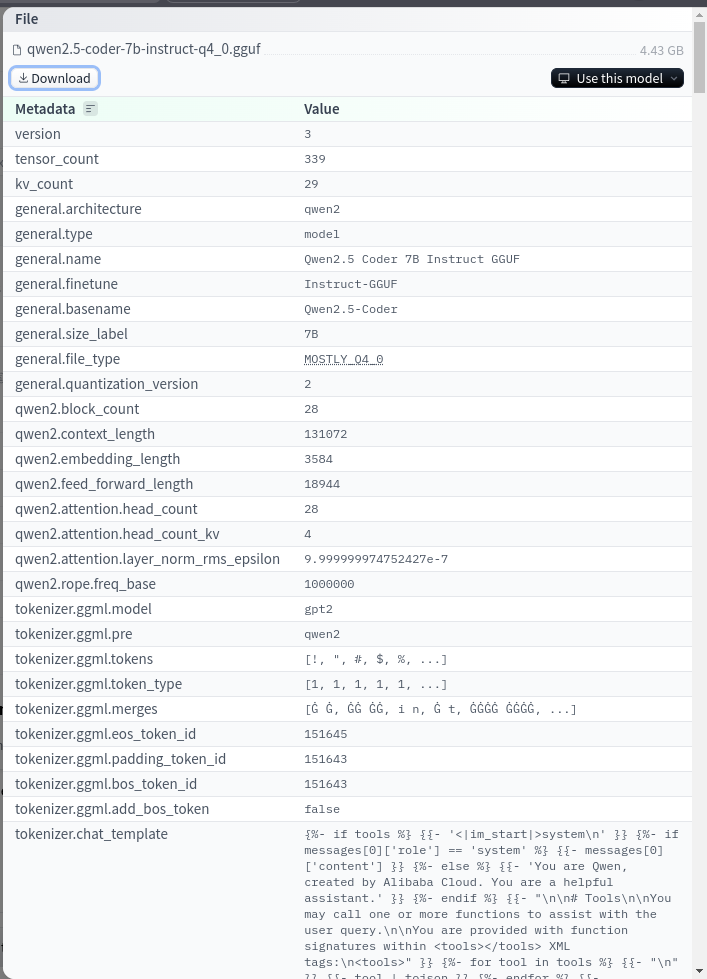
На открывшейся странице будет информация о параметрах версии и кнопка "Download". Нажимаем на неё и дожидаемся завершения скачивания.
Что учитывать при скачивании?
- Размер модели. Обратите внимание на размер файла:
- Большие модели могут занимать десятки гигабайт даже в сжатом формате.
- Убедитесь, что у вас достаточно места на диске.
- Скорость интернета.
Если файл слишком большой, скачивание может занять много времени. Используйте менеджеры загрузок, чтобы избежать прерываний.
Использование модели
Квантированные модели можно применять по-разному:
- В качестве чата (самый распространённый сценарий).
- В проектах, интегрируя модель через код.
- Запуская веб-сервер для работы с моделью по API.
В этом посте мы рассмотрим только использование модели как чата. Если вам интересны другие сценарии, дайте знать в комментариях!
Мы разберём два инструмента: llama.cpp и LM Studio.
Использование llama.cpp
llama.cpp — это лёгкий и кроссплатформенный инструмент для работы с моделями семейства LLaMA (Large Language Model Meta AI). Его основное преимущество — эффективная работа на процессорах, что делает его идеальным для пользователей без мощных видеокарт.
Ключевые особенности llama.cpp:
- Оптимизация под CPU — позволяет запускать модели без GPU.
- Компактность — поддерживает квантованные версии моделей (например, 4-bit и 8-bit), снижая требования к оперативной памяти.
- Кроссплатформенность — работает на Windows, macOS, Linux и Android.
- Интеграция — предоставляет API для использования в других приложениях.
Проект подходит для локального использования моделей без облачных сервисов, сохраняя конфиденциальность.
Скачиваем программу с актуальной страницы релизов:
- Для Windows с Nvidia GPU — выбираем
win-cuda-cu12.2.0-x64. - Для Linux — используем
ubuntu-x64. Подойдёт для большинства дистрибутивов. - Для macOS — выбираем версию для вашего процессора:
macos-x64(Intel) илиmacos-arm64(M-процессоры).
После скачивания распаковываем архив, переходим в директорию и открываем терминал.
llama.cpp поддерживает запуск веб-сервера с простым интерфейсом. Для его запуска используем команду:
./llama-server -m qwen2.5-coder-7b-instruct-q4_0.gguf --port 8080
Здесь qwen2.5-coder-7b-instruct-q4_0.gguf — это путь до модели, которую вы скачали. В данном примере модель находится в той же директории.
После запуска в терминале появится процесс инициализации. Когда вы увидите строку: main: server is listening on http://127.0.0.1:8080 - starting the main loop
это означает, что сервер успешно запущен.
Открываем в браузере адрес http://127.0.0.1:8080. Появится веб-интерфейс:
Теперь можно использовать модель как обычный чат:
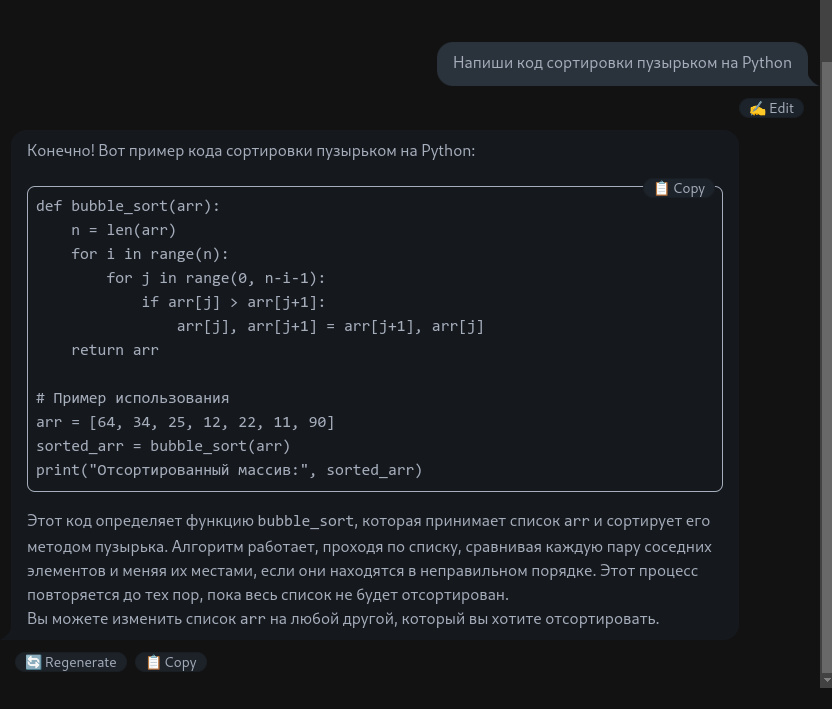
Использование LM Studio
LM Studio — удобный графический интерфейс для работы с локальными языковыми моделями, ориентированный на пользователей, которые предпочитают визуальное взаимодействие вместо работы через терминал.
Ключевые особенности LM Studio:
- Поддержка локальных моделей — оптимизирована для LLaMA и совместимых моделей.
- Интуитивный интерфейс — простота настройки и использования даже для начинающих.
- Гибкость параметров — позволяет менять настройки генерации текста (длина ответа, температура, частота и др.).
- Работа оффлайн — обеспечивает независимость от интернета, повышая конфиденциальность.
На главной странице скачиваем версию для вашей операционной системы.
- Для Windows программа устанавливается стандартным способом.
- Для Linux перед запуском нужно выдать файлу права на выполнение:
chmod +x ./LM_Studio-0.3.5.AppImage
(замените LM_Studio-0.3.5.AppImage на имя вашего файла).
После запуска вас встретит дружелюбный интерфейс:
Язык приложения можно изменить в настройках (иконка шестерёнки в правом нижнем углу).
Добавление локальной модели
LM Studio использует строгие правила для распознавания моделей. Чтобы добавить модель:
- Создайте удобную директорию для моделей.
- В этой директории создайте папку с именем поставщика модели, например,
Qwen. - Внутри создайте папку с названием модели из Hugging Face, например,
Qwen2.5-Coder-7B-Instruct-GGUF. - Поместите файл модели (GGUF) в эту папку.
- В приложении откройте вкладку "Мои модели" (иконка папки слева-сверху).
- Рядом с "Каталог моделей" нажмите три точки -> "Изменить..." и укажите созданную директорию.

Скачивание модели через LM Studio
Вместо ручного скачивания, LM Studio позволяет загрузить модели напрямую. Для этого:
- Перейдите на вкладку с лупой (четвёртая слева-сверху).
- Откроется список моделей с Hugging Face.
- Найдите нужную модель, выберите формат квантирования и нажмите "Download".

После завершения скачивания модель появится в списке "Мои модели". 
Запуск чата
Для запуска чата:
- Перейдите на первую вкладку.
- Вверху по центру нажмите "Выберите модель для загрузки". Откроется список доступных моделей.

- Выберите модель и настройте параметры запуска, например, длину контекста (чем больше контекст, тем выше требования к видеокарте).

- Нажмите "Загрузить модель". После загрузки модель готова к использованию.
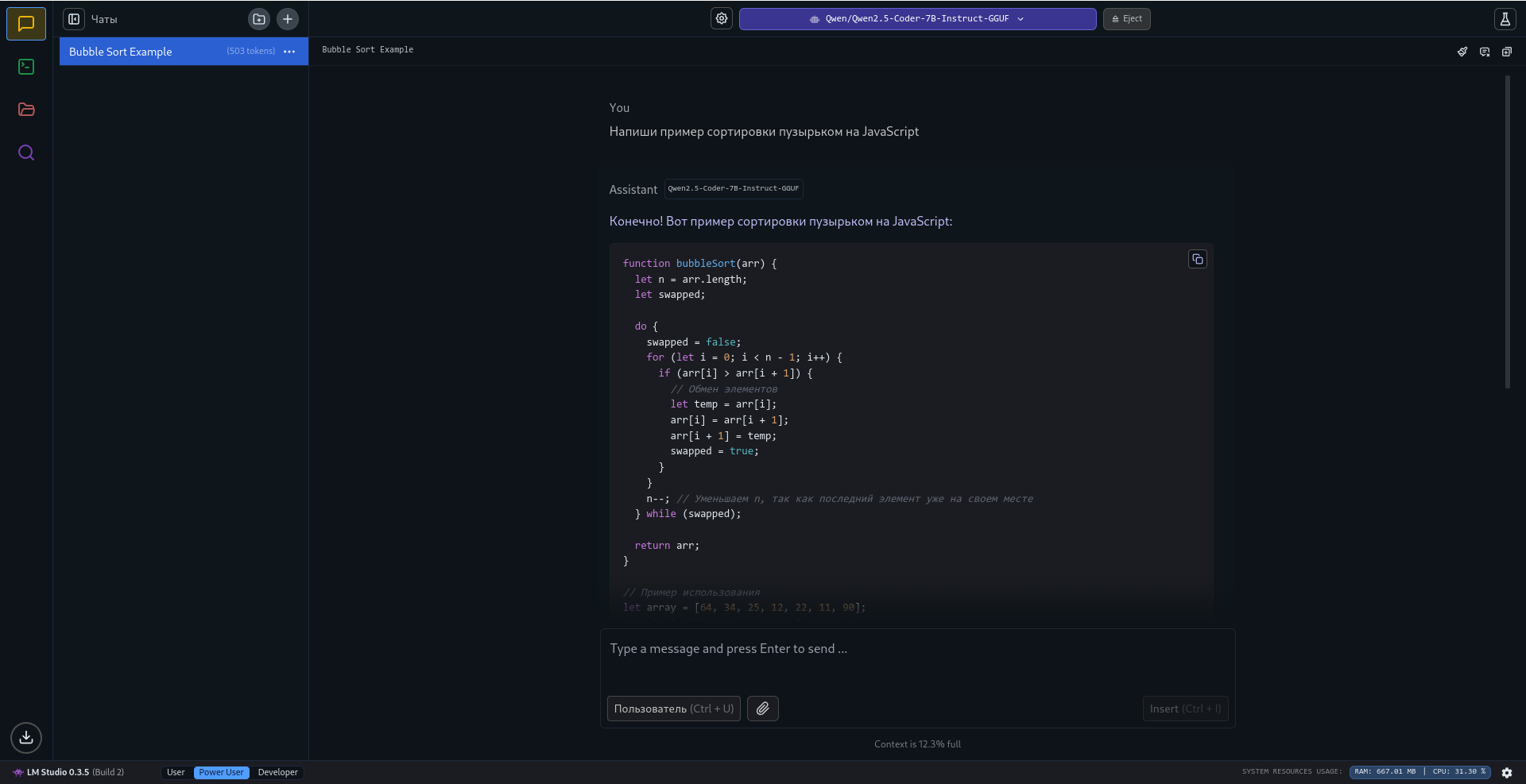
Чат доступен в этом же окне:
Теперь можно задавать вопросы и общаться с моделью!
Заключение
Разобравшись в этом процессе, можно сказать, что это лишь малая часть огромного мира LLM-моделей. Их применение действительно многообразно: от чат-ботов, работающих без интернета, до создания полноценных программных продуктов на базе таких моделей. Если этот пост был полезен и вам интересно продолжение, я подумаю над тем, как можно использовать эти модели в реальных проектах.
P.S. Было бы неправильно писать пост про LLM и не воспользоваться им. Часть поста написана с использованием Qwen2.5-Coder-32B-Instruct-GGUF, а затем проверена на ошибки ChatGPT. Безусловно, не стоит слепо полагаться на выдаваемый моделью результат. Всегда нужно проверять и править, тем не менее, LLM-модели оказывают хорошее подспорье в процессе, объясняя нюансы или просто правя текст.
Если вам интересны подобные материалы, подписывайтесь на Telegram-канал «Код на салфетке». Там я делюсь гайдами для новичков, полезными инструментами и практическими примерами из реальных проектов.

Комментарии