
Любому веб-приложению нужен веб-сервер для доступа извне. На самом деле, многие даже не уделяют выбору веб-сервера для своего приложения достаточного внимания: на Django берут "популярный" Gunicorn (а кто-то ещё и обвязывает его Uvicorn'ом), а для FastAPI Uvicorn практически стандарт. Тут "на сцену" выходит Granian, представляющий впечатляющие результаты производительности с простой настройкой.
В своём проекте "Код на салфетке" я использовал uWSGI, но недавно узнал про новый Granian и мне стало интересно на что он способен. Так появилась идея для этой статьи.
В этой статье узнаем:
- Что такое веб-сервер и какие у них есть интерфейсы взаимодействия.
- Какие есть популярные WSGI и ASGI веб-серверы.
- Сравним их производительность.
Что такое веб-сервер
Веб-сервер, в рамках применения в Python, это программа, которая запускает Python-приложение и обеспечивает его взаимодействие с внешним миром по протоколу HTTP (или другим, если необходимо, например, WebSocket).
Веб-сервер принимает внешние запросы, передаёт их в приложение через интерфейс (WSGI, ASGI или RSGI), а затем возвращает ответ. Проще говоря, веб-сервер — это связующее звено между кодом и пользователем.
Воркеры и процессы — это ключевые понятия для понимания работы веб-серверов:
- Воркер (worker) — это отдельный процесс или поток, который обрабатывает входящие запросы.
- Процесс — это независимая программа в операционной системе со своей памятью.
Использование нескольких воркеров позволяет обрабатывать запросы параллельно, что увеличивает производительность.
Интерфейсы взаимодействия
Для "общения" между веб-сервером и приложением существует три интерфейса взаимодействия:
- WSGI (Web Server Gateway Interface).
- ASGI (Asynchronous Server Gateway Interface).
- RSGI (Rust Server Gateway Interface).
Разберём подробнее каждый.
WSGI (Web Server Gateway Interface)
Стандарт интерфейса между Python-приложением и веб-сервером, появившийся ещё в Python 2.2 (PEP 333, потом обновлён до PEP 3333).
- Синхронный интерфейс взаимодействия — обрабатывает запросы один за другим.
- Применяется преимущественно в "классических" фреймворках, вроде Django или Flask.
- Не поддерживает WebSocket, SSE (Server-Sent Events) и некоторые другие возможности.
Достаточно простой интерфейс, подходящий для небольших и низконагруженных приложений.
ASGI (Asynchronous Server Gateway Interface)
Современный стандарт интерфейса для Python-приложений. Придуман как "духовный наследник" WSGI.
- Синхронный и асинхронный интерфейс взаимодействия — может обрабатывать множество запросов одновременно.
- Применяется в "молодых" фреймворках, вроде FastAPI, а также может применяться в Django (через Channels) или Flask.
- Поддерживает WebSocket, SSE, HTTP/2 и так далее.
Актуальный интерфейс взаимодействия для больших и высоконагруженных приложений.
RSGI (Rust Server Gateway Interface)
Новый проект (2024-2025), вдохновлённый WSGI/ASGI, но созданный с прицелом на Rust + Python экосистему. Его продвигают разработчики Granian и Uvicorn.
- Идея: минималистичный интерфейс между веб-сервером и приложением.
- Оптимизирован для Rust-бэкендов и Python-приложений, чтобы убрать избыточные прослойки.
- Цель — заменить ASGI/WSGI в будущих фреймворках.
- Поддерживает синхронные, асинхронные и нативные Rust-хендлеры.
- Акцент на высокую производительность и простоту (ASGI со временем оброс сложностями).
Экспериментальный интерфейс, появившийся совсем недавно. Может проявить себя в высоконагруженных приложениях, написанных на Python, или комбинированных системах, использующих не только Python, но и Rust.
Python веб-серверы
Веб-серверов для Python много, но мы разберём и сравним только несколько — те, которые чаще всего встречаются в обучающих статьях, а также рассмотрим на их фоне Granian.
Обратите внимание! Производительность и потребление ресурсов собраны из разных источников и чаще всего описывают "Hello World" тесты. Значения усреднены и могут отличаться на реальных проектах, поскольку на производительность влияет не только сам веб-сервер, но и оптимизация приложения.
Gunicorn (WSGI)
Лёгкий WSGI-сервер для Python (Green Unicorn). Широко используется с Django/Flask. Работает по схеме prefork (несколько процессов-воркеров).
- Конфигурация: простая. Например,
gunicorn --workers 4 myproject.wsgi:application. Хорошо масштабируется на нескольких ядрах. Формула расчета воркеров: рекомендуется число воркеров ≈ (2 × количество CPU ядер) + 1. - Особенности: реализует только WSGI, не поддерживает ASGI/async "из коробки". Для работы с асинхронными задачами можно применять сторонние классы воркеров (gevent/eventlet) или использовать
gunicorn+uvicorn-воркеры. Не имеет встроенной поддержки WebSocket (только HTTP). - Производительность: хорошие показатели для синхронных нагрузок. ~3 000-10 000 запросов/сек — в зависимости от числа воркеров, окружения, нагрузки. При этом память на воркер ~30 MB.
Установка:
pip install gunicornЗапуск (Django):
gunicorn --workers 4 myproject.wsgi:applicationЗапуск (Flask):
gunicorn --workers 4 "myapp:app"uWSGI (WSGI)
"Полноценный" веб-сервер/приложение-сервер. Поддерживает WSGI, FastCGI, HTTP и др. Можно использовать в режиме префорк или с потоками/Greenlets.
- Конфигурация: очень гибкая и сложная. Требует конфигурационного файла (uwsgi.ini) с множеством опций (процессы, потоки, кеширование, балансировка). Из-за богатого набора опций порог вхождения высок.
- Особенности: предназначен для высоких нагрузок и масштабируемых систем (например, Emperor mode, multiple apps). Поддерживает горячую замену кода, кэширование и балансировку процессов.
- Производительность: несколько лучше, чем у Gunicorn в бенчмарках: 10-12 тысяч запросов/сек. Память на воркер чуть выше — 40 MB.
Установка:
pip install uwsgiЗапуск (Django):
uwsgi --http :8000 --module myproject.wsgi:application --processes 4 --threads 2Запуск (Flask):
uwsgi --http :8000 --module myapp:app --callable appПример uwsgi.ini:
[uwsgi]
module = myproject.wsgi:application
master = true
processes = 4
threads = 2
http = :8000Uvicorn (ASGI)
Лёгкий ASGI-сервер для Python. Построен на основе uvloop и httptools (Cython). Предназначен для асинхронных приложений (Starlette, FastAPI, Django Channels).
- Конфигурация: очень простая. Запускается одной командой:
uvicorn myapp.asgi:application --workers 4. Не имеет сложных конфигов, можно задавать параметры в CLI или скрипте Python. - Особенности: поддерживает HTTP/1.1, HTTP/2, WebSocket. Имеет низкий оверхед и малый размер кода, использует готовые асинхронные event loop (uvloop).
- Производительность: высокая: ~35 000-40 000 запросов/сек. Низкая задержка. Память на воркер примерно 20 MB.
Установка:
pip install uvicorn[standard]Запуск (FastAPI):
uvicorn main:app --workers 4 --reloadЗапуск (Django Channels):
uvicorn myproject.asgi:application --workers 4Granian (WSGI, ASGI, RSGI, Rust)
Новый HTTP-сервер для Python-приложений, написанный на Rust (использует Hyper/Tokio). Поддерживает сразу WSGI, ASGI и RSGI-интерфейсы.
- Конфигурация: простой CLI или кодовый API. Например,
granian --interface asgi myapp:appдля запуска ASGI-приложения. Можно задавать количество процессов/потоков. - Особенности: ориентирован на максимальную производительность и пропускную способность. Из коробки поддерживает HTTP/1, HTTP/2, WebSocket'ы, HTTPS, статические файлы. Можно конфигурировать SSL/mTLS, расширения ASGI. Лёгкий (нет проблем с GIL, может использовать Rust-потоки).
- Производительность: очень высокая: ~40 000-45 000 запросов/сек в ASGI-режиме и ~40 000 запросов/сек в WSGI-режиме. Максимальная пропускная способность. Память на процесс ~15 MB.
GIL (Global Interpreter Lock) — это механизм в Python, который позволяет выполнять только один поток Python-кода одновременно. Это ограничение влияет на производительность многопоточных приложений, но не касается многопроцессных решений.
Установка:
pip install granianЗапуск (FastAPI / ASGI):
granian --interface asgi main:app --workers 4Запуск (Django WSGI):
granian --interface wsgi myproject.wsgi:application --workers 4Запуск (Django Channels):
granian --interface asgi myproject.asgi:application --workers 4Запуск (FastAPI / RSGI — экспериментально):
main.py:
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello from RSGI + FastAPI"}Команда запуска:
granian --interface rsgi main:app --workers 4Важно: RSGI не поддерживается существующими фреймворками вроде Django или Flask, поэтому применять его можно только с библиотеками/фреймворками, изначально рассчитанными на асинхронный стек. Для FastAPI RSGI может дать буст, но для Django он неприменим (на момент написания статьи).
Сравнение производительности
RPS и Latency — важные метрики производительности:
- RPS (Requests Per Second) — количество запросов, которые сервер может обработать за секунду.
- Latency (задержка) — время, которое требуется для обработки одного запроса.
RPS (запросов в секунду):
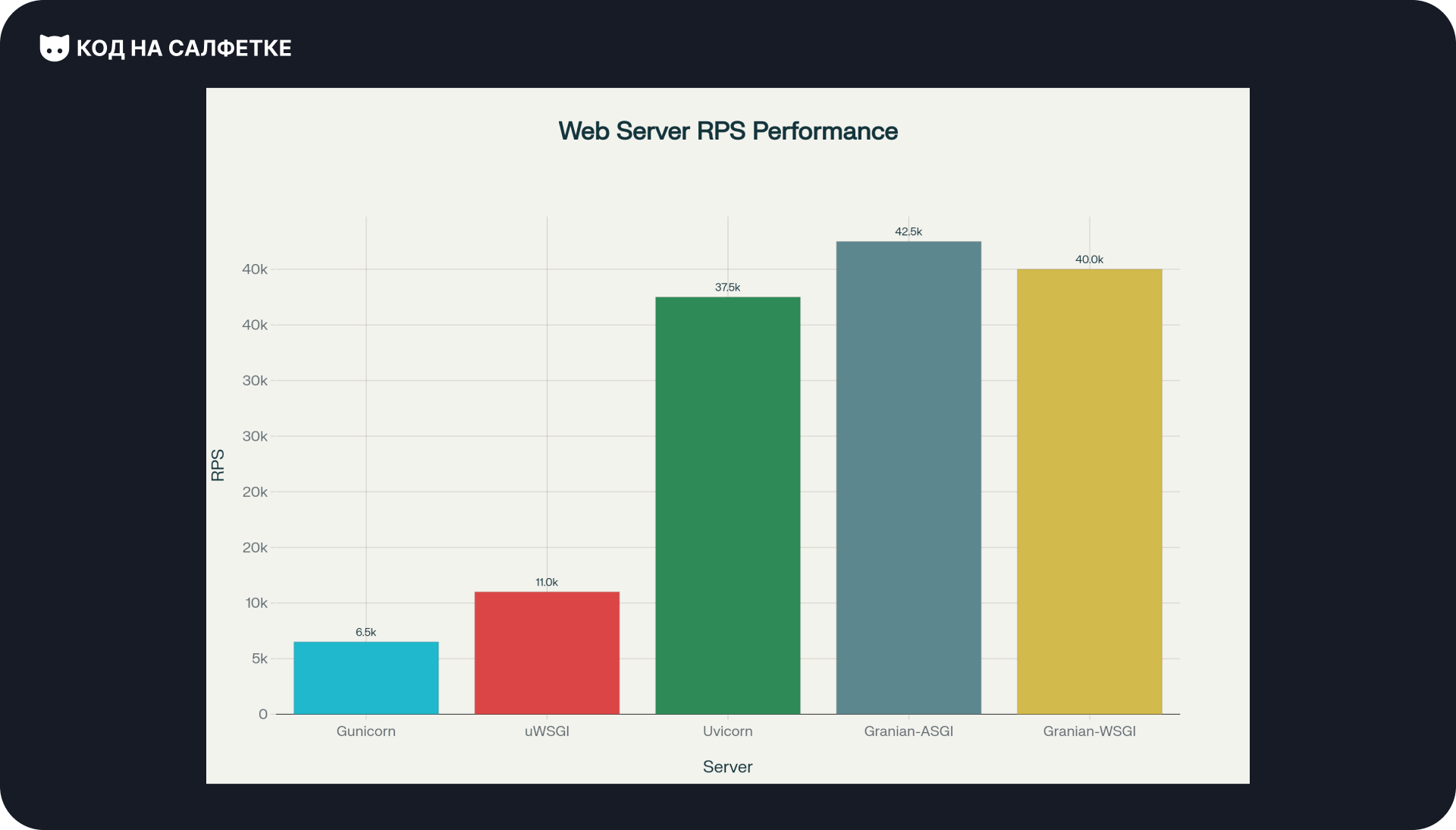
- Gunicorn: ~3 000–10 000 запросов/сек.
- uWSGI: 10 000–12 000 запросов/сек.
- Uvicorn: ~35 000–40 000 запросов/сек.
- Granian:
- ASGI: ~40 000–45 000 запросов/сек.
- WSGI: ~40 000 запросов/сек.
Вывод по производительности: ASGI-серверы (Uvicorn, Granian) показывают значительно лучшие результаты по количеству обрабатываемых запросов в секунду по сравнению с традиционными WSGI-серверами. Granian демонстрирует лучшие показания благодаря оптимизациям на Rust и отсутствию ограничений GIL.
Потребление памяти:
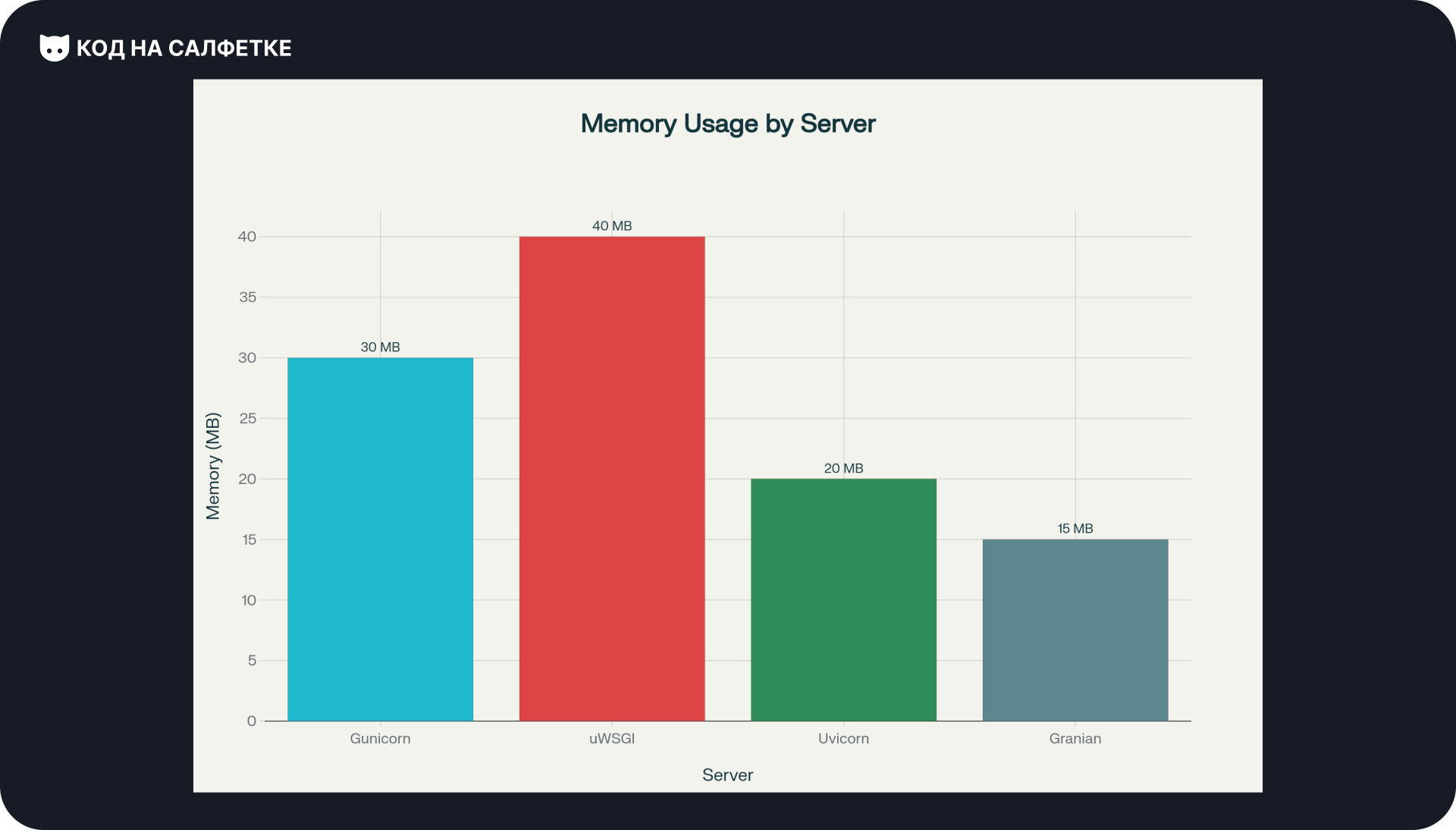
- Gunicorn: ~30 MB на воркер.
- uWSGI: ~40 MB на воркер.
- Uvicorn: ~20 MB на воркер.
- Granian: ~15 MB на воркер.
Вывод по памяти: Granian показывает наименьшее потребление памяти благодаря эффективной реализации на Rust. Uvicorn также демонстрирует хорошие показатели. Традиционные WSGI-серверы потребляют больше памяти из-за особенностей архитектуры Python и дополнительных слоев абстракции.
Задержка (Latency):

- Gunicorn: ~6-12 мс (средняя задержка).
- uWSGI: ~4-8 мс (средняя задержка).
- Uvicorn: ~2-5 мс (средняя задержка).
- Granian:
- ASGI: ~0.7-1.2 мс (средняя задержка).
- WSGI: ~1.5-2.5 мс (средняя задержка).
Вывод по задержкам: Granian демонстрирует исключительно низкую задержку во всех режимах работы. ASGI-реализация показывает субмиллисекундные задержки, что критично для высокочувствительных к латентности приложений. Даже в WSGI-режиме Granian превосходит традиционные серверы по этой метрике.
Пара слов о Granian
Приложения на Rust всё чаще проникают в закулисья Python-библиотек. Первой ласточкой был "нашумевший" пакетный менеджер uv, обеспечивший высокую скорость работы с окружением проекта. Теперь о себе заявляет Granian как новый и, что немаловажно, быстрый веб-сервер.
Ради интереса, перед написанием статьи я решил попробовать его в работе с Django.
Как я упомянул во вступлении, на сайте использовался uWSGI — он неплох, но его главный минус в сложности настройки для новичков. Запуск веб-сервера выглядел так:
command: ["uwsgi", "--ini", "/code/uwsgi.ini"]Замена на Granian не вызвала вообще никаких проблем, поскольку ему не нужны конфиг-файлы и он запускается одной командой:
command: [
"granian",
"--interface", "wsgi",
"--host", "0.0.0.0",
"--port", "8000",
"--workers", "2",
"--backpressure", "30",
"--workers-lifetime", "3600",
"--log-level", "info",
"pressanybutton.wsgi:application"
]Настройка параметров Granian
Количество воркеров рассчитывается по той же формуле: (2 × количество CPU ядер) + 1. Для контейнера с 1 CPU достаточно 2-3 воркеров.
Backpressure — это механизм контроля нагрузки. Параметр --backpressure 30 означает, что если в очереди накопилось 30 запросов, сервер начнёт отклонять новые подключения. Это защищает от перегрузки. Для стандартных лимитов PostgreSQL в 100 одновременных подключений, backpressure 30 — разумное значение, оставляющее запас для других процессов.
Workers-lifetime — время жизни воркера в секундах. Через 3600 секунд (1 час) воркер перезапускается, что помогает избежать утечек памяти.
Заключение
Безусловно, в статье упомянуты далеко не все существующие веб-серверы для Python-проектов. Я старался брать те, которые "на слуху", то есть фигурируют в гайдах или книгах. Несмотря на это, получившееся сравнение наглядно демонстрирует разницу в производительности между классическими синхронными (WSGI) и современными асинхронными (ASGI) подходами. Особенно выделяется Granian, предоставляющий в WSGI-режиме схожую с ASGI производительность.
Основные выводы:
- ASGI-серверы значительно превосходят WSGI по производительности
- Granian показывает лучшие результаты как по скорости, так и по потреблению памяти
- Выбор сервера зависит от требований проекта: для простых приложений достаточно Gunicorn, для высоконагруженных — Uvicorn или Granian
- Rust-решения в Python-экосистеме становятся трендом, обеспечивая лучшую производительность
Напишите в комментарии ваши мысли по поводу увеличения роли Rust-приложений в Python-библиотеках, а также каким веб-сервером пользуетесь вы! Интересно будет почитать.

Комментарии