
Сначала я думал, что CI/CD – нечто сложное и чуждое разработчику, но понял, что ни один проект – будь то фриланс, Open Source или пет-проект – не может обойтись без этой практики, которая значительно повышает эффективность работы.
Статьи по теме:
- В статье "Docker 6. Собственный GIT-сервис - Гид по быстрому запуску Gitea на вашем сервере!" мы с вами развернули собственный Git-сервер на базе Gitea;
- В статье "Подключаем Runner для CI/CD в Gitea" мы подключили Runner к репозиторию, а также узнали, что из себя представляет CI/CD.
В этой статье:
- Повторим теорию про CI/CD;
- Рассмотрим примеры использования CI/CD на моих проектах;
- Разберём как написать свой Workflow для GitHub/Gitea Actions.
Почему GitHub/Gitea Actions?
GitHub/Gitea Actions глубоко интегрирован в репозиторий, что устраняет необходимость использования сторонних сервисов для автоматизации. Простота настройки, возможность создавать собственные сценарии и богатая экосистема готовых решений делают этот инструмент отличным выбором для разработки и доставки программного обеспечения.
Поскольку Gitea Actions совместима с GitHub Actions, то рассказанное в этой статье будет применимо к обоим сервисам.
Почему не затронем GitLab?
GitLab не будем рассматривать, поскольку структура документа отличается и сравнивая пайплайны GitHub и Gitlab трудно будет рассказать в рамках этой статьи так, чтобы сохранить главное.
Немного теории
Основные понятия CI/CD
Чтобы понять, как работают CI/CD, важно разобраться в их основных компонентах и принципах. Эти два понятия — Continuous Integration (Непрерывная интеграция) и Continuous Delivery/Deployment (Непрерывная доставка/развёртывание) — тесно связаны, но решают разные задачи.
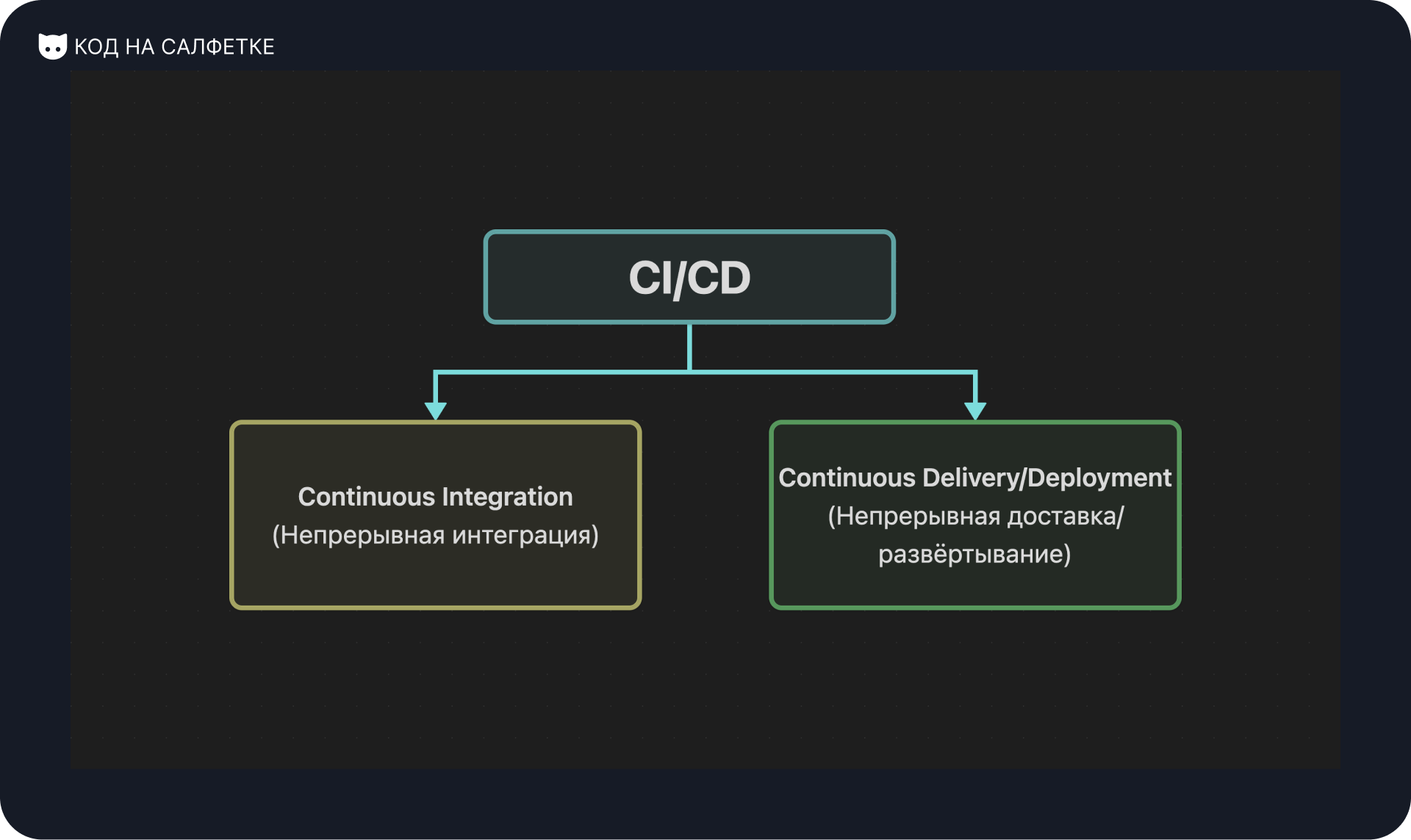
Определение CI (Continuous Integration)
Непрерывная интеграция (CI) — это практика, при которой разработчики регулярно объединяют свои изменения в общий репозиторий, что автоматически инициирует сборку и тестирование для оперативного выявления ошибок.
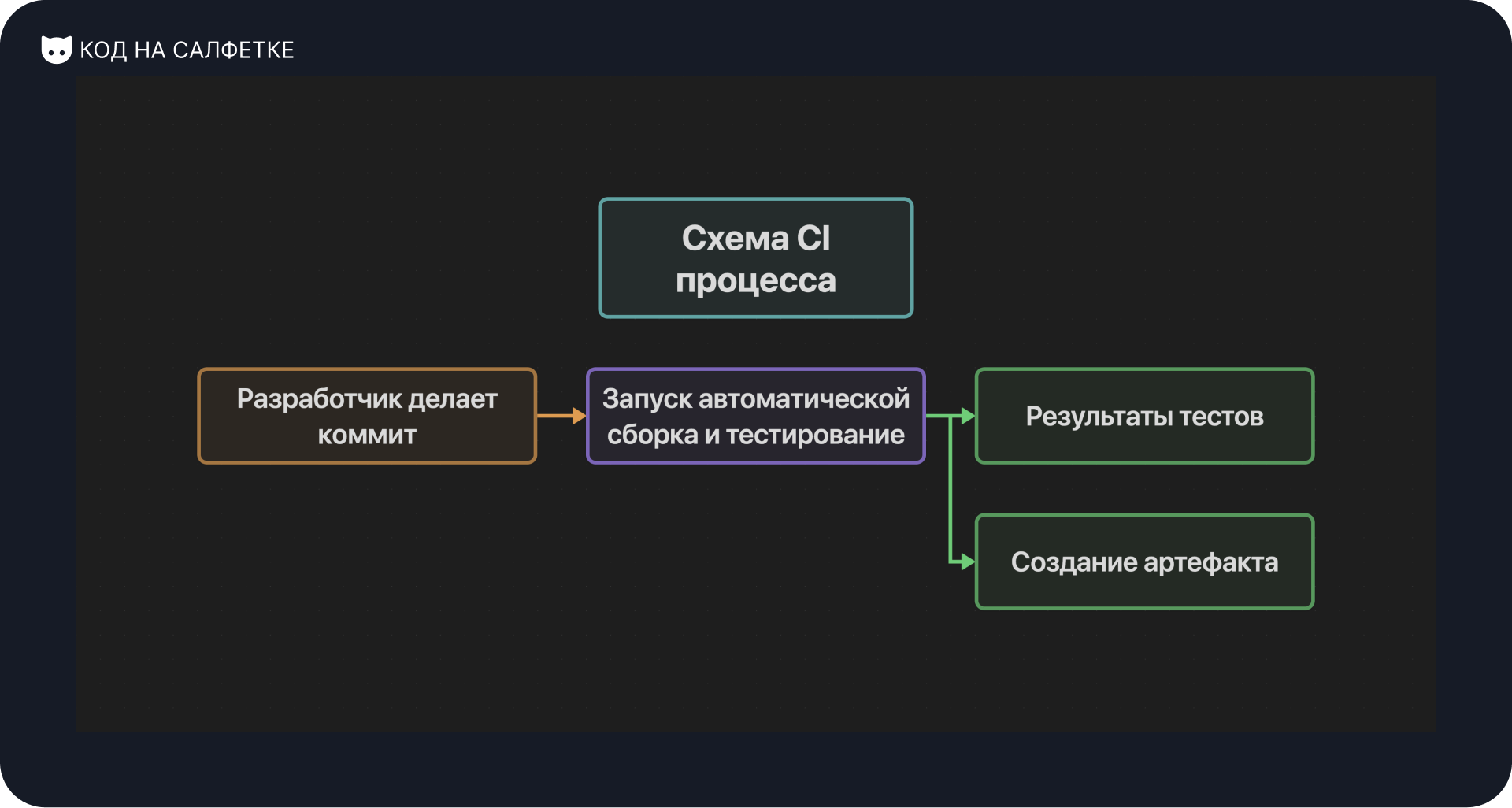
Основные принципы CI:
- Частое слияние кода: Разработчики интегрируют свои изменения в основную ветку как можно чаще, чтобы избежать конфликтов и накопления ошибок;
- Автоматизированное тестирование: Каждый коммит запускает набор тестов (юнит-тесты, интеграционные тесты), чтобы убедиться, что изменения не сломали существующий функционал;
- Сборка проекта: После успешного прохождения тестов код автоматически собирается в готовый к развёртыванию артефакт.
Ситуация:
Представьте гипотетического джуна Василия: он устроился на свою первую работу и занимается разработкой веб-приложения. Василий, в силу недостатка опыта, допускает много ошибок и после каждого пуша, на него ругается тимлид и отправляет все переделывать. Неприятная ситуация, правда?Но однажды руководство решает внедрить обязательную проверку линтера и автоматического запуска тестов. После внедрения CI - Василий после каждого пуша видит, что в его коде есть ошибки и оперативно исправляет их, надеясь, что тимлид отвлекся :)
Определение CD (Continuous Delivery / Continuous Deployment)
Непрерывная доставка (Continuous Delivery) и непрерывное развёртывание (Continuous Deployment) — это шаги после CI, автоматизирующие процесс доставки кода в различные среды, такие как тестовая, staging или production.
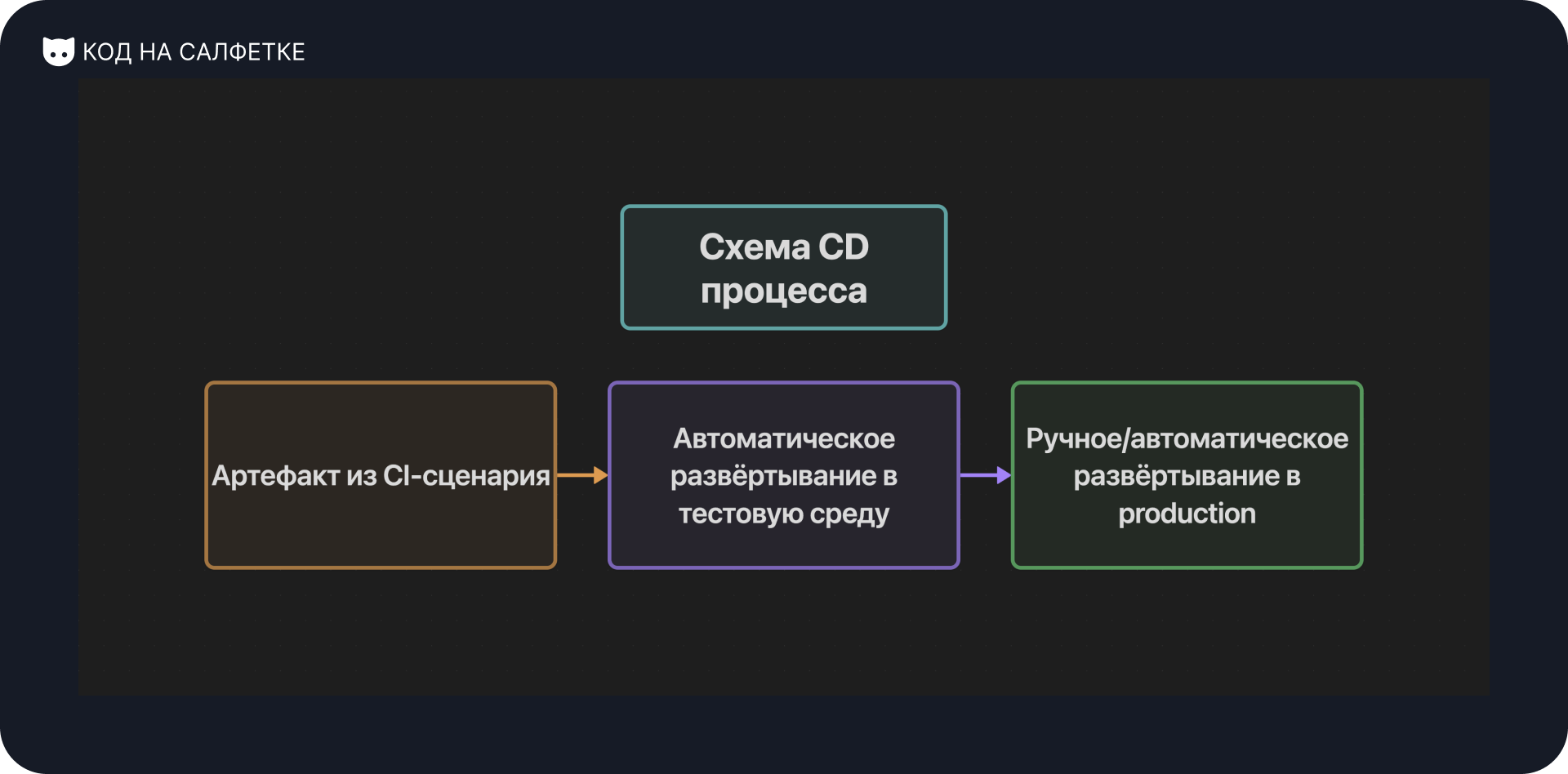
Различие между Continuous Delivery и Continuous Deployment:
- Continuous Delivery подразумевает, что код после успешной сборки и тестирования автоматически подготавливается к развёртыванию, но окончательное решение о выпуске принимается вручную;
- Continuous Deployment идёт дальше: код автоматически развёртывается в production без ручного вмешательства, если все тесты пройдены успешно;
Основные принципы CD:
- Автоматизированное развёртывание: Процесс доставки кода в различные среды (тестовая, staging, production) максимально автоматизирован;
- Минимизация ручных шагов: Чем меньше ручных действий, тем быстрее и надёжнее процесс выпуска новой версии продукта.
Ситуация:
Представьте гипотетического DevOps Петра: Он пришёл в компанию где работает Василий и ужаснулся! Все процессы связанные с его областью работы - выполняются в ручном режиме. Порой выпуск новых изменений в прод-среду занимал больше недели из-за того, что нужно было всё проверить, выполнить необходимые миграции и прочее. Всё это часто приводило к человеческим ошибкам и проблемам на готовом продукте.Именно он настоял на внедрении CI/CD: автоматическая система развёртывания больше не требовала ручной работы, проверки всех изменений, создания и применения миграций. Всё это ускорило выход нового функционала в продакшн среде.
Артефакты в CI/CD
Артефакты — это файлы, созданные в процессе сборки и тестирования проекта. Они могут включать в себя скомпилированные бинарные файлы, сжатые архивы, контейнерные образы, журналы тестов и другие ресурсы, необходимые для дальнейшего развёртывания.
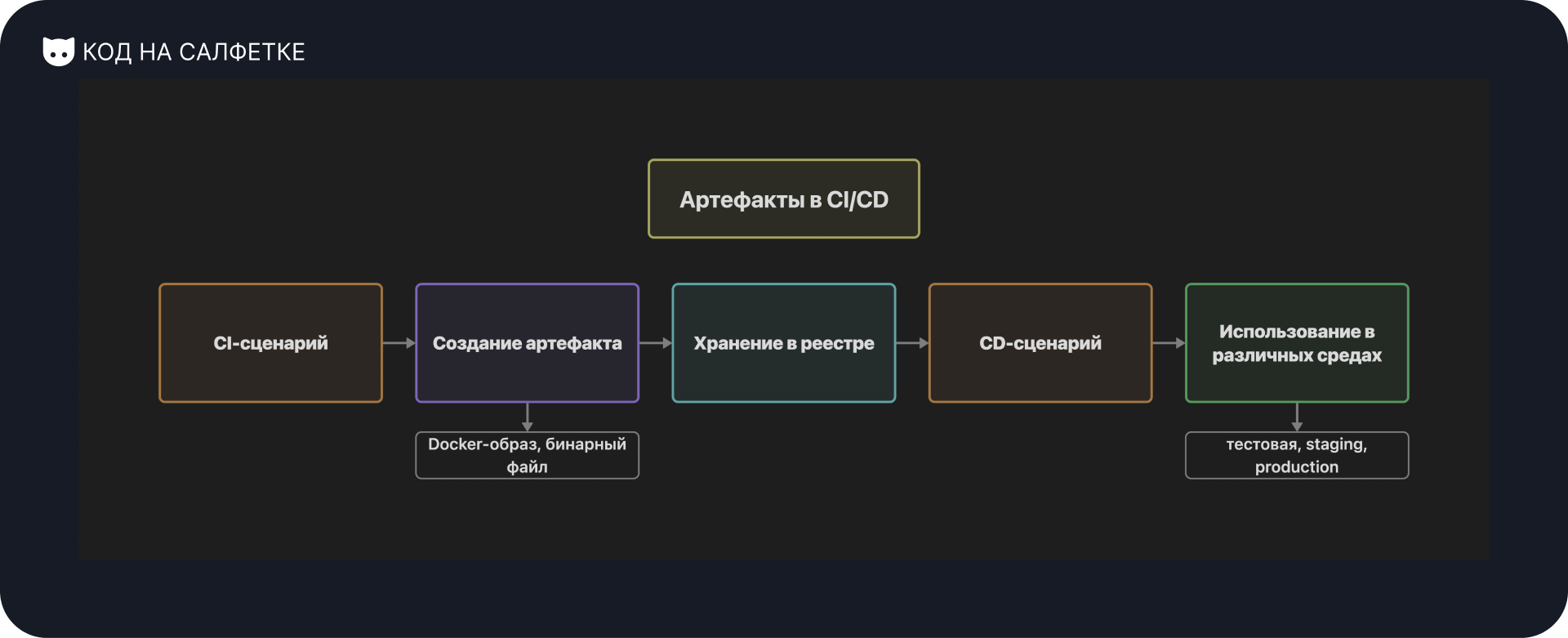
Примеры артефактов:
- Скомпилированные исполняемые файлы (например,
.jar,.exe,.bin); - Docker-образы, готовые к деплою в контейнерные среды;
- Архивы с файлами приложения (
.zip,.tar.gz); - Логи тестов и отчёты о покрытии кода.
Зачем нужны артефакты?
- Повторяемость сборок: Артефакты позволяют использовать один и тот же собранный код на всех этапах развертывания, избегая несовместимостей;
- Быстрое восстановление: В случае отката версии можно взять артефакт предыдущей сборки;
- Разделение процессов: Разработчики, тестировщики и DevOps-инженеры могут работать с одним и тем же артефактом без необходимости пересобирать код.
Ситуация:
Вспоминаем про Петра и Василия: Василий выполняет свою задачу, пушит в репозиторий и открывает Pull Request из своей ветки в основную ветку разработки. После этого его тимлид, удостоверившись, что задача выполнена и, что в кой-то веки нет ошибок принимает его PR и инициализирует мерж.Но Пётр предусмотрел и такой сценарий: в нём происходит финальное тестирование с учётом новых изменений от Василия, а затем создается артефакт - Docker-образ с актуальной версией проекта.
По окончании CI, запускается процесс CD: используя собранный артефакт проекта, происходит деплой его на прод-сервер в автоматическом режиме. Таким образом CI/CD объединяет работу всех участвующих в процессе людей.
Преимущества использования CI/CD
Внедрение CI/CD в процесс разработки дает массу преимуществ, без которых трудно представить современные проекты.
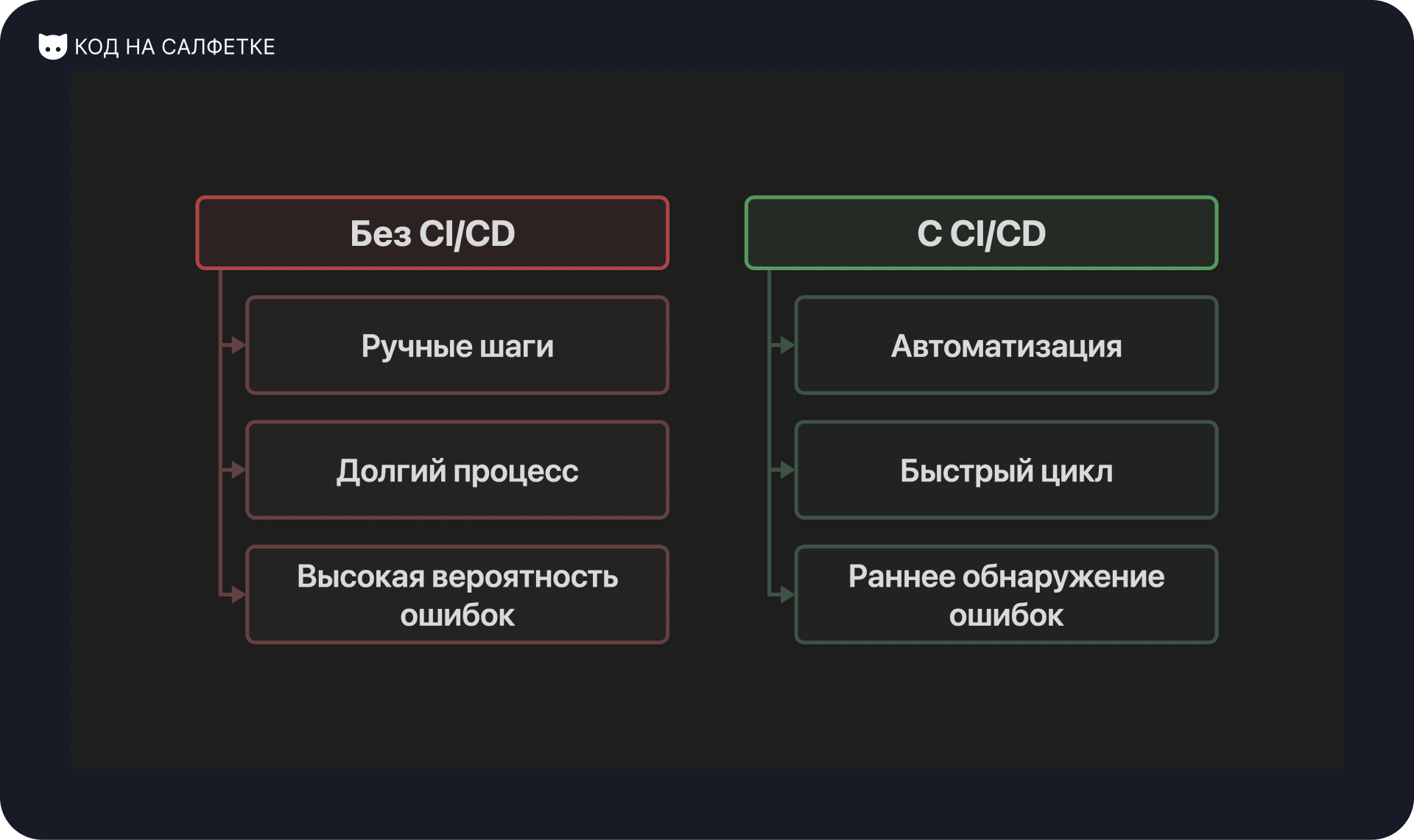
Сокращение времени разработки
Одним из главных преимуществ CI/CD является ускорение цикла разработки. Благодаря автоматизации процессов, разработчики могут быстро интегрировать свои изменения в основную кодовую базу. Это позволяет:
- Раннее обнаружение ошибок: Проблемы выявляются сразу после коммита, что упрощает их исправление;
- Минимизацию конфликтов: Частое слияние кода снижает вероятность сложных конфликтов при интеграции. Таким образом не накапливается много изменений на стороне разработчиков приводящих к конфликтам при слиянии.
Повышение качества ПО
Автоматизация тестирования и проверки кода — это ключевой фактор повышения качества программного обеспечения. CI/CD обеспечивает:
- Автоматизированное тестирование: Юнит-тесты, интеграционные и функциональные тесты выполняются при каждом изменении кода;
- Статический анализ: Инструменты проверяют код на соответствие стандартам и выявляют потенциальные уязвимости;
- Стабильность: Постоянное тестирование снижает риск появления ошибок в production.
Удобство развёртывания
CI/CD делает процесс развёртывания быстрым и надёжным. Это особенно важно для проектов, где требуется частое обновление функционала. Преимущества включают:
- Автоматизированное развёртывание: Код автоматически доставляется в тестовую, staging и production среду;
- Минимизация ручных шагов: Чем меньше ручных действий, тем ниже вероятность ошибок;
- Гибкость: Возможность быстро откатить изменения в случае проблем.
Нужно ли простому разработчику знать CI/CD, если он не DevOps?
Несмотря на то, что CI/CD традиционно ассоциируется с областью DevOps, базовые знания о принципах непрерывной интеграции и доставки полезны для любого разработчика.
Во-первых, даже если вы не настраиваете сам процесс CI/CD, знание его механизмов помогает понять, что происходит с вашим кодом после коммита. Вы узнаёте, как изменения проходят проверку, какие тесты запускаются и какие артефакты создаются.
Во-вторых, умение работать с CI/CD-пайплайнами делает вас более эффективным участником команды. Вы сможете не только писать код, но и участвовать в обсуждении улучшения процессов разработки, предлагать автоматизацию рутинных задач, а также лучше взаимодействовать с DevOps-инженерами. Такой слаженный подход способствует быстрой интеграции новых фич и снижению времени на поиск и устранение ошибок.
В-третьих, знание CI/CD открывает возможности для личного профессионального роста. В современном мире разработки автоматизация становится стандартом, и даже базовые навыки в этой области могут стать вашим конкурентным преимуществом. Это знание помогает не только улучшать текущие процессы, но и внедрять новые технологии и методики, способствующие развитию всей команды.
Таким образом, даже если ваша специализация не связана с настройкой инфраструктуры, понимание принципов CI/CD становится важным инструментом для создания качественного, стабильного и масштабируемого продукта.
Примеры использования CI/CD в реальных проектах
Разберём некоторые примеры применения CI/CD в моих личных и командных проектах.
Пример 0: Сайт "Код на салфетке"
Сайту "Код на салфетке" уже почти два года. В нём регулярно что-то обновляется и улучшается, по мере наличия свободного времени, конечно. И на нём у нас всё ещё не подключен CI/CD.
Как сейчас выглядит внедрение изменений?
- Локально вносятся изменения в код;
- Используя sFTP, обновлённые файлы отправляются на сервер (да, можно было использовать git, но порой надо что-то быстро поправить прямо на сервере и тогда с гитом были бы проблемы);
- Подключившись по SSH к серверу выполняется пересборка образа с сайтом.
Это пример того, как много действий необходимо выполнить, чтобы внедрить изменения в prod-среду.
Возникающие проблемы:
- Человеческий фактор - когда нужно за раз изменить много файлов, легко запутаться и что-то не отправить на сервер, а потом выяснять причину ошибок.
- Низкая эффективность - среднее время деплоя проекта с CI/CD примерно 2-3 минуты, а в случае с салфеткой может варьироваться "от пары минут до бесконечности". Тем самым снижая эффективность внедрения нового функционала на сайт.
- Разные окружения - локальная разработка и сервер имеют разные окружения и настройки, это порой вызывает проблемы, когда сделал что-то локально, но, например, не учёл пути внутри Docker-контейнера.
Так почему я не сделаю Workflow для автоматизации этого процесса?
Всё дело в том, что изначально сайт был написан "на коленке" и точно также была устроена инфраструктура на сервере. Конечно, со временем что-то изменялось и улучшалось, но внедрение автоматизации потребует серьёзных переработок всего, что есть сейчас, а на это, к сожалению, пока нет свободного времени.
Пример 1: Taigram
В нашем Open Sourse проекте Taigram мы сразу начали внедрять CI/CD.
На данный момент, в нём есть два workflow:
- Первый проверяет код линтерами и запускает PyTest при каждем пуше;
- Второй срабатывает при мержке Pull Request'а в main-ветку.
Код сценариев доступен в нашем GitHub-репозитории.
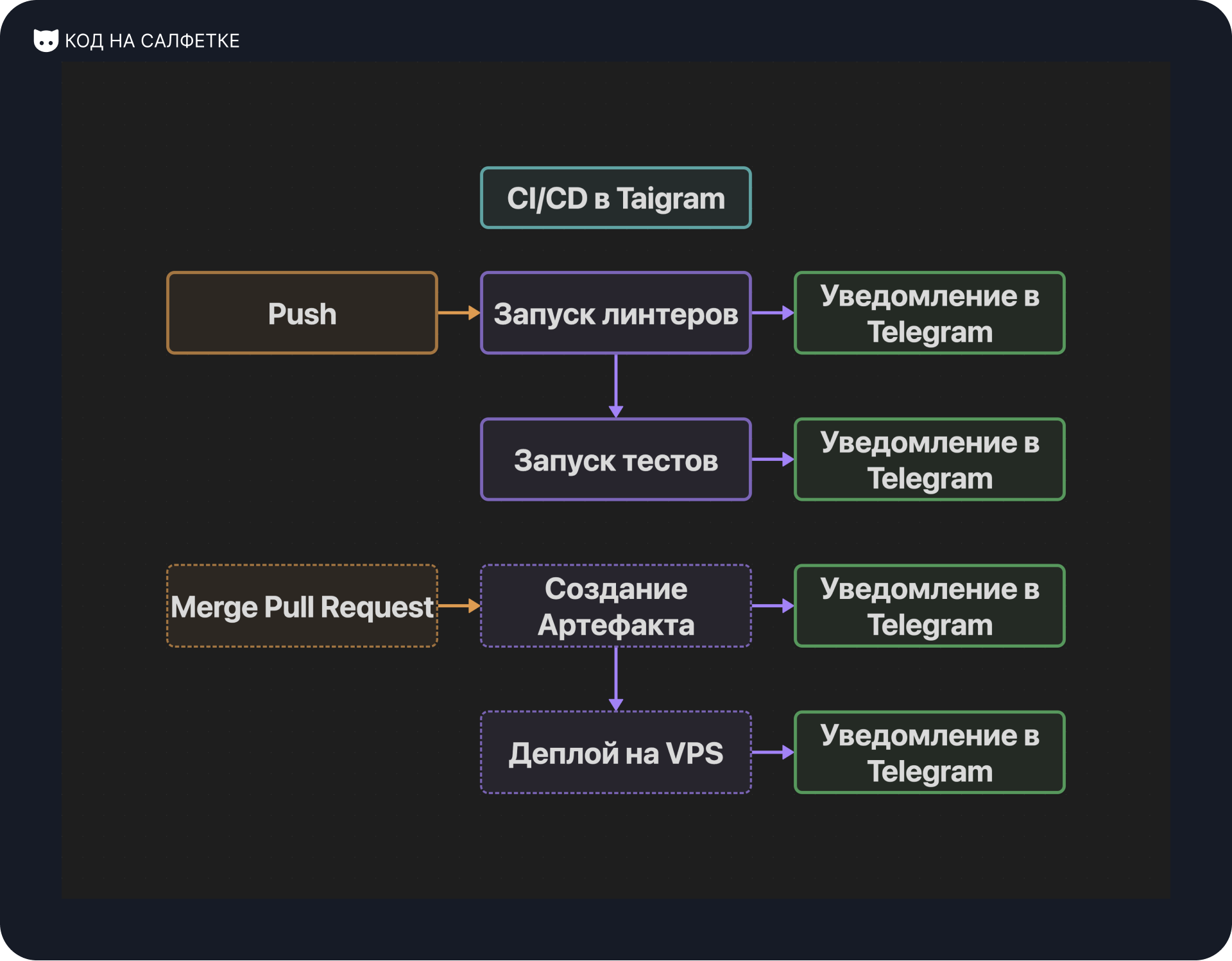
Workflow Lint and Test
Этот Workflow срабатывает при каждом пуше в не main-ветку.
Затем выполняются две задачи:
lint, запускающийpre-commit;test, запускающийPyTest.
В конце каждой задачи, независимо от результата линтеров или тестов, выполняется действие actions-telegram-notifier по отправке уведомления в Telegram.
Workflow Notify on Merged Pull Request
Этот Workflow срабатывает когда Pull Request переходит в состояние "Закрыт".
Затем в задаче notify проверяется, что закрытый Pull Request был смержен с целевой веткой и если условие положительное, отправляет уведомление в Telegram.
Workflow деплоя
На данном этапе разработки, в деплое пока нет необходимости. Однако, когда проект войдёт в минимально работоспособную стадию, будет добавлен Workflow для деплоя проекта.
Пример 2: Сервис Авторизации Код на Салфетке
Мы работаем над централизованным сервисом авторизации для нескольких проектов. Хоть об этом и рано пока писать, там применяется CI/CD не только для линтеров и тестов, но и для деплоя фронтенда и бэкэнда.
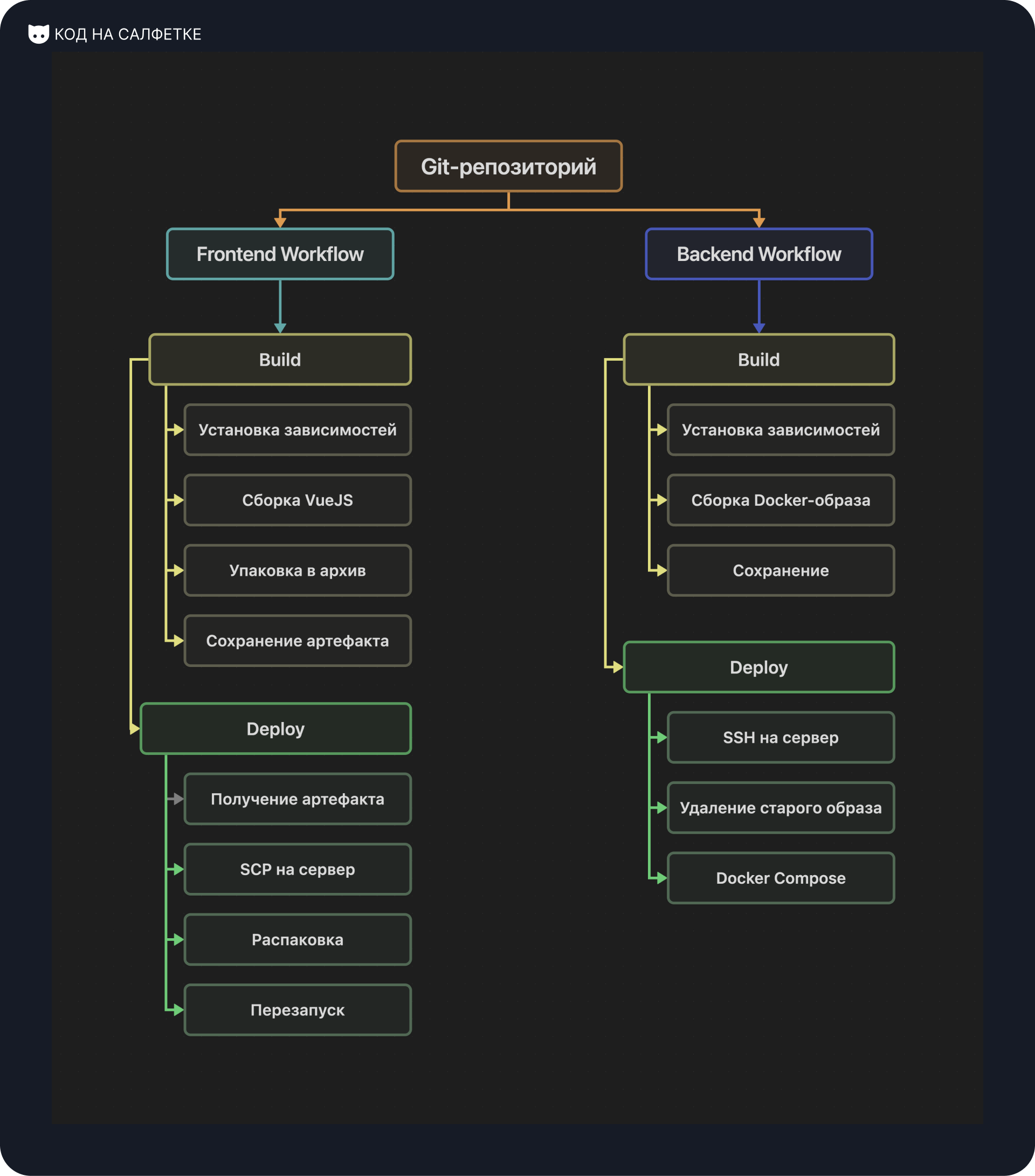
Wokflow деплоя фронтенда
В качестве фронтенда у нас VueJS, а раздаёт его веб-сервер Caddy.
В нашем Workflow два действия (не считая линтера): build и deploy.
В действии build устанавливаются зависимости, происходит сборка проекта, результат сборки запаковывается в архив и сохраняется как артефакт в репозитории.
В действии deploy, получаем артефакт, подключаемся к серверу по SCP, загружаем и распаковываем и в конце перезагружаем сервис с Caddy, чтобы он увидел обновлённые файлы.
Workflow для бэкэнда
Бэкэнд у нас написан на Python с использованием FastAPI.
Тут также два действия: build и deploy, но работают они чуть иначе.
В действии build, помимо стандартных установок зависимостей, происходит сборка и сохранение Docker-образа в Container Registry (в нашем случае в Gitea).
Затем в действии deploy подключаемся по SSH к серверу, удаляем старый образ, запускаем Docker Compose, который сам подтягивает новый образ.
Итог по примерам
Как можете видеть, на практике CI/CD оказывается очень полезным инструментом. Мне очень нравится прописывать процесс, собирая его "по кирпичикам" и потом наблюдать как всё выполняется само, без вмешательств и лишних затрат времени.
Разбираем структуру Workflow на практике
По большому счёту, Workflow пишутся по одному "шаблону", а различаются используемыми инструментами (Actions) и выполняемыми действиями.
В одной из своих статей "Подключаем Runner для CI/CD в Gitea", помимо запуска Runner'а, я привёл пример простейшего Workflow. Давайте подробнее разберём как написать свой на примере Workflow для запуска линтеров.
Файл Workflow
Каждый Workflow представляет собой отдельный файл в формате YAML. Назвать его можно как угодно, но желательно отражать суть происходящего, например, lint_and_test.yaml.
Файлы располагаются в специальной директории внутри репозитория:
- Для Gitea это -
.gitea/workflows - Для GitHub это -
.github/workflows
Каждый файл будет запускаться независимо друг от друга и иметь свою "область видимости". Разделяются запускаемые файлы по условиям срабатывания, о которых дальше.
Название и условия срабатывания
Самая первая строчка в файле это ключ name. В нём прописывается название Workflow, которое можно будет видеть на странице выполняемых действий.
Например:
name: Build and deploy Docker containerДалее идёт ключ on:
on:В блоке этого ключа прописываются условия (триггеры) срабатывания workflow.
Вот некоторые из них:
push- запускается при отправке коммитов в репозиторий.
on:
push:
branches:
- main
tags:
- 'v*'
paths:
- 'src/**'pull_request- срабатывает при создании, обновлении или закрытии pull request'ов.
on:
pull_request:
branches:
- mainschedule- позволяет настроить автоматический запуск по расписанию с помощью cron-выражения.
on:
schedule:
- cron: '0 0 * * *'issues- срабатывает при создании или изменении issue в репозитории.
on:
issues:
types: [opened, edited, milestoned]Более подробно о доступных триггерах можно прочитать в документации GitHub.
В триггерах есть и свои условия, например:
- Для событий push и pull_request:
branches- указывает список веток, для которых будет срабатывать workflow. Можно использовать точные имена или шаблоны (например,feature/*)branches-ignore- задает ветки, изменения в которых не должны приводить к запуску workflowtags- позволяет запускать workflow только при пуше определенных тегов (например, версии с префиксомv)tags-ignore- исключает запуск workflow при пуше определенных теговpaths- фильтрует изменения по путям файлов. Workflow запустится, если измененные файлы соответствуют указанным шаблонамpaths-ignore- исключает запуск workflow, если изменения затрагивают указанные файлы или директории
- Дополнительные варианты:
- Для
pull_request:types- позволяет фильтровать событияpull_requestпо типу:opened,edited,synchronize,reopened,closedи др. Это помогает запускать workflow только для определенных действий. - Для
schedule:cron- позволяет указать cron-выражение для срабатывания workflow, например,'0 0 * * *'будет срабатывать каждый день в полночь.
- Для
Пример для запуска линтеров:
name: Lint Project
on:
push:
branches-ignore:
- mainВ данном примере, workflow срабатывает на каждый пуш, кроме пуша в main-ветку.
Задачи/job'ы/действия
Далее идёт основной ключ jobs. В блоке этого ключа описываем выполняемые задачи. Прописываем каждую задачу как отдельный вложенный ключ, например:
jobs:
lint:
...
test:
...Названия задач вы придумываете сами исходя из того, что делает эта задача.
Про запуск тестирования и другие сценарии поговорим в других статьях, сейчас сосредоточимся на содержимом одной задачи.
На данный момент наш workflow выглядит так:
name: Lint Project
on:
push:
branches-ignore:
- main
jobs:
lint:Основа задачи lint
Внутри блока задачи прописывается конфигурация, необходимая для выполнения этой задачи.
Доступны следующие параметры:
name- задает отображаемое имя задачи в интерфейсе GitHub Actions.
name: "Lint Code"runs-on- указывает на используемый Runner'ом Docker-образ. Подробнее описано статье "Подключаем Runner для CI/CD в Gitea".
runs-on: ubuntu-latestneeds- определяет зависимость от других задач. Задача запустится только после успешного завершения указанных.
needs: buildif- условное выражение для запуска задачи. Позволяет выполнять задачу, только если условие истинно.
if: github.ref 'refs/heads/main'env- определяет переменные окружения, доступные всем шагам в задаче.
env:
MY_VAR: valuedefaults- задает настройки по умолчанию для шагов (например, рабочий каталог).
defaults:
run:
working-directory: srctimeout-minutes- ограничивает время выполнения задачи. Если задача превышает указанное время, она будет остановлена.
timeout-minutes: 30strategy- позволяет задать матрицу сборки, чтобы запускать задачу параллельно с разными параметрами.
strategy:
matrix:
node: [12, 14]container- позволяет запускать задачу внутри указанного контейнера, что может быть полезно для использования определённого окружения.
container:
image: node:14services- определяет сервисные контейнеры, которые будут запущены параллельно с задачей (например, базы данных или кэш-серверы).
services:
redis:
image: redis
ports:
- 6379:6379concurrency- позволяет ограничивать одновременное выполнение задачи или отменять предыдущие запуски при новом запуске.
concurrency:
group: lint
cancel-in-progress: trueoutputs- определяет выходные данные задачи, которые могут быть использованы в других задачах.
outputs:
result: ${{ steps.my_step.outputs.result }}Параметров много и все они дают обширные возможности по настройке конкретных задач под свои нужды.
Для нашего примера достаточно двух параметров: name и runs-on:
name: Lint Project
on:
push:
branches-ignore:
- main
jobs:
lint:
name: Run Linter
runs-on: ubuntu-latestБлок steps
Ещё один, не упомянутый выше параметр, а скорее блок - steps. В этом блоке в виде списка/массива (перечисление через символ -) указываются выполняемые в данной задаче шаги.
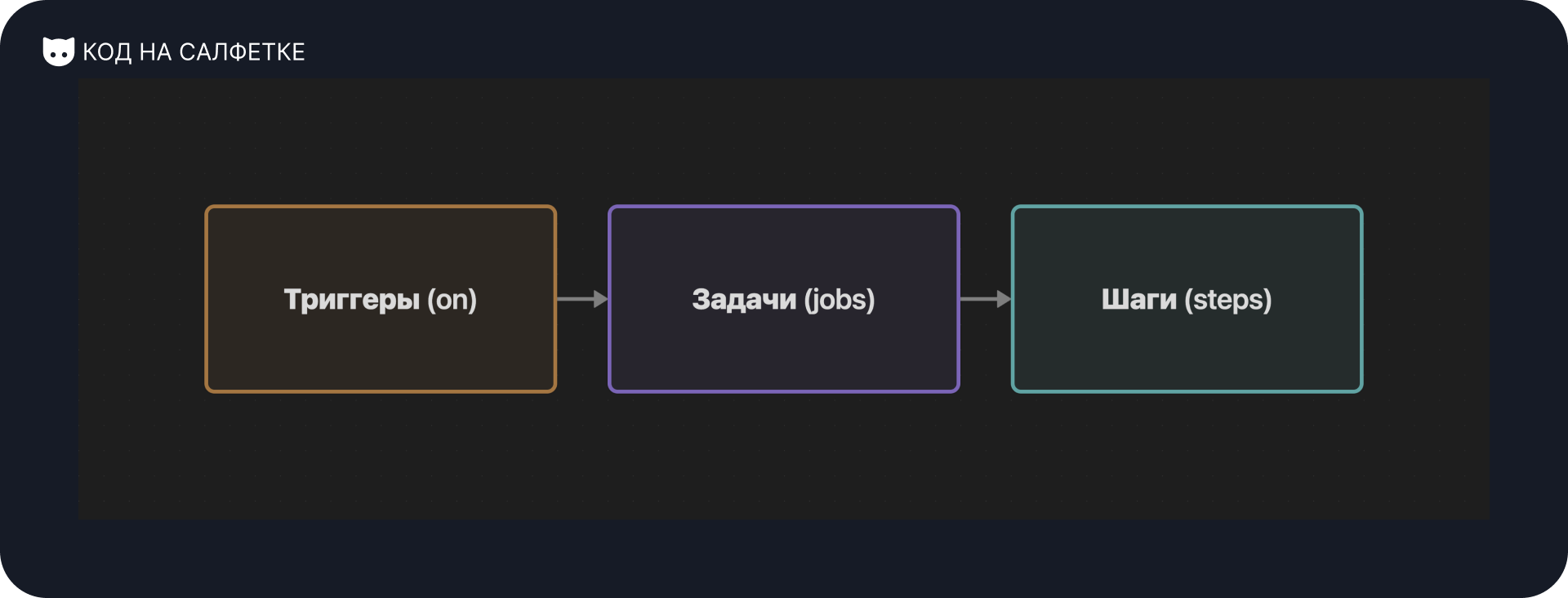
Основные типы шагов
- Шаг с выполнением команд (run)
run- команда (или последовательность команд) для выполнения в shell.shell- указывает, какой интерпретатор использовать (например,bash,sh,pwshи т.д.). Если не указан, используется shell по умолчанию.working-directory- задает рабочую директорию, в которой будет выполнена команда.
Пример:
- name: Run a shell command
run: |
echo "Hello, world!"
ls -la
shell: bash
working-directory: ./scripts- Шаг с использованием готового action (uses)
uses- ссылается на сторонний или собственный action, который загружается из репозитория или Docker образа. Найти готовые actions можно в маркетплейсе GitHub или написать самостоятельно, например, actions-telegram-notifier.with- передает входные параметры для action. Структура параметров зависит от конкретного action.
Пример:
- name: Checkout code
uses: actions/checkout@v4
with:
fetch-depth: 0
Общие параметры, доступные для всех шагов
Помимо ключевых run и uses, к шагу можно добавить дополнительные настройки:
name- отображаемое имя шага, которое помогает понять, что происходит в конкретном шаге.id- уникальный идентификатор шага, позволяющий ссылаться на его выходные данные в последующих шагах.if- условное выражение, позволяющее выполнять шаг только при соблюдении определённых условий (например, выполнение шага только для определённой ветки или при успешном завершении предыдущего шага).env- определяет переменные окружения, доступные только в рамках этого шага.continue-on-error- если установлено вtrue, позволяет продолжать выполнение workflow, даже если шаг завершился с ошибкой.timeout-minutes- ограничивает время выполнения шага. Если шаг превышает заданное время, он будет остановлен.outputs- позволяет задать выходные данные шага, которые могут быть использованы в других шагах (обычно в комбинации с ключомid).
Пример шага с несколькими дополнительными параметрами:
- name: Generate version number
id: version_step
run: echo "::set-output name=version::1.2.3"
env:
BUILD_ENV: production
timeout-minutes: 5И затем можно обратиться к выходным данным:
- name: Use generated version
run: echo "Version is ${{ steps.version_step.outputs.version }}"Применяем шаги
В нашем Workflow с линтером потребуется несколько шагов:
Checkout repository
- name: Checkout repository
uses: actions/checkout@v4Что делает:
Этот шаг использует официальный action actions/checkout для клонирования (checkout) репозитория в рабочую среду (runner). Это необходимо для того, чтобы все файлы проекта были доступны для последующих шагов, таких как установка зависимостей или выполнение тестов.
Set up Python
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: "3.12"Что делает:
Шаг настраивает окружение с нужной версией Python с помощью action actions/setup-python. Параметр python-version: "3.12" указывает, что в рабочей среде должна быть установлена именно версия Python 3.12. Это важно для корректной работы проекта, особенно если он требует конкретной версии интерпретатора.
Install dependencies
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pre-commit installЧто делает:
Этот шаг выполняет последовательность команд в терминале:
python -m pip install --upgrade pip: Обновляет менеджер пакетовpipдо последней версии.pip install -r requirements.txt: Устанавливает зависимости проекта, перечисленные в файлеrequirements.txt.pre-commit install: Настраиваетpre-commit hooks, что позволяет автоматически запускать проверочные скрипты перед фиксацией изменений в репозитории.
Run pre-commit
- name: Run pre-commit
run: pre-commit run --all-files --hook-stage manualЧто делает:
Этот шаг запускает pre-commit hooks вручную для всех файлов в репозитории:
pre-commit run: Команда для выполнения настроенных хуков.--all-files: Указывает, что хуки должны быть запущены для всех файлов, а не только для изменённых.--hook-stage manual: Определяет стадию запуска хуков как «manual» (ручной).
Итоговый вариант выглядит следующим образом:
name: Lint Project
on:
push:
branches-ignore:
- main
jobs:
lint:
name: Run Linter
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: "3.12"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pre-commit install
- name: Run pre-commit
run: pre-commit run --all-files --hook-stage manualКак Василий CI/CD на пет-проекте настраивал
Василия очень заинтриговали нововведения на его работе и он захотел подробнее разобраться во всём. Благо у него как раз был один пет-проект, энтузиазм на разработку которого, по правде говоря, немного иссяк. И вот с горящими глазами он вернулся к проекту и решительно заявил: "Я его наконец-то доделаю!".
Проект у него, можно сказать, почти был готов, но только локально. Он решил начать с малого, наткнувшись на эту статью, он узнал, что из себя представляет CI/CD и как с ним работать. Написал свой первый Workflow для линтера по примеру и он сразу заработал! Радости Василия не было предела.
Следующим шагом он решил добавить тестирование своего кода. Для этого он сперва написал тесты почти ко всему своему коду, а затем принялся за Workflow. Тут у него возникли проблемы с запуском тестов! Из-за некорректного запуска, его тесты не срабатывали, но он разобрался во всём.
Линтеры и тесты есть, проект готов к работе и даже покрыт тестовыми сценариям. Настало время деплоя! Задача непростая, т.к. он умел обращаться с Linux и Docker, но как написать сценарий автоматизации? Начал он со сборки Docker-образа в CI-сценарии. Нашёл необходимый Action для этого, изучил, что для увеличения производительности нужно использовать кэширование и вот на его странице репозитория в GitHub в блоке Packages виднеется свежесобранный образ проекта.
Он понял логику построения процессов и с CD-сценарием деплоя не возникло проблем. Он изучил варианты и остановился на подключении по SSH к серверу и запуск там свежего образа. На удивление, всё заработало с первого раза!
Довольный своими успехами Василий добавил новый навык в своё резюме и задумался о расширении своих профессиональных обязанностей, но это уже другая история.
Заключение
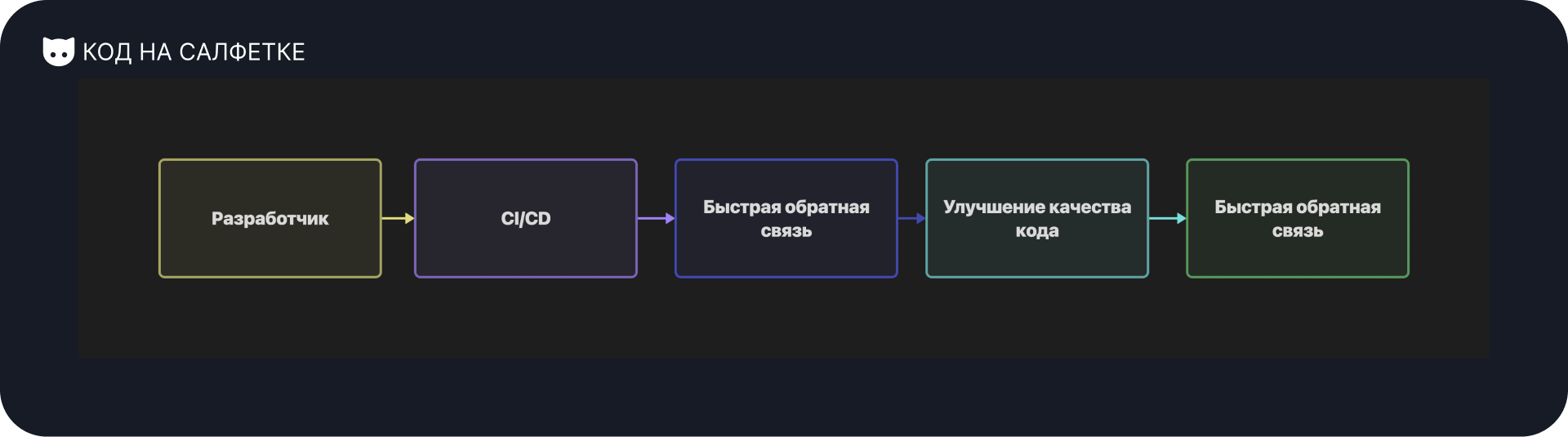
Как показывает практика, пренебрегать CI/CD не стоит, и чем раньше автоматизация процессов появится в ваших проектах, тем продуктивнее окажется работа над проектом.
На первый взгляд может показаться, что это всё сложно, но на деле оказывается своего рода "конструктором", в котором мы по блокам составляем процесс Workflow. Обилие готовых Action только способствуют упрощению работы с CI/CD, но ничто не мешает вам написать свой собственный Action, который будет выполнять то, что нужно вам.
Был бы рад почитать о ваших сценариях применения CD/CD при работе над проектами и том, как они повлияли на вашу работу.
Также, если вам интересна тема статьи, но хочется больше узнать, напишите, что вас интересует и возможно это станет темой одной из следующих статей!

Комментарии
Оставить комментарийВойдите, чтобы оставить комментарий.
Спасибо вспомнил как работать с actions)