
Всем привет!
Мы продолжаем работу над нашим Open Source проектом Taigram!
Прошлая статья "Taigram: Начало работы", можно сказать, была посвящена организационным моментам:
- Описанию проекта;
- Создание доски и планированию задач;
- Создание репозитория с инициализированном в
uvпроектом.
Также мы объявили, что находимся в поиске разработчиков и к нам присоединились 2 человека: Роман и Виктор. О их вкладе мы расскажем в последующих статьях.
Ну, а начиная с этой статьи будет больше кода и технических деталей.
Рассказ будем вести в "полу-хронологическом" порядке, т.е. будем идти по пути разработки, но из-за того, что в процессе многие вещи так или иначе корректировались, будем учитывать эти корректировки, чтобы не повторяться в будущем.
Оговоримся сразу: Цель этой и следующих статей не написать гайд, не разобрать написанный код "по строкам". Цель заключается в том, чтобы рассказать как мы пришли к такому решению, попытаться обосновать его с надеждой, что кому-то это будет полезно или мы получим обратную связь.
Структура проекта
Каждому проекту нужна чёткая и понятная структура, но она зависит от ряда факторов.
Традиционно есть две крайности:
- Если это небольшой скрипт на десяток другой кода, то вероятно ему подойдёт "всё в main.py-файле". Это не будет казаться чем-то страшным, поскольку ему больше и не надо.
- Если это большое веб приложение с множеством модулей и зависимостей, то тут удобным будет применение DDD-архитектуры (Domain Driven Design). Такая структура проекта сделает его гибким к изменениям и расширению.
В нашем случае требовалась "золотая середина", поскольку проект относительно небольшой, хоть и с перспективами на развитие (об этом как нибудь потом). Пообщавшись, поспорив и смирившись мы договорились до удобной для нас структуры проекта.
Мы разбили вcё на пакеты по "логическим" блокам, чтобы, скажем БД была в одном месте, а обработчики в другом. Актуальная на момент написания структура выглядит так:
taiga_wh_notifier
├── config
├── logs
├── src
│ ├── core
│ │ └── Base
│ ├── entities
│ │ ├── callback_classes
│ │ ├── enums
│ │ ├── schemas
│ │ │ ├── base_data
│ │ │ ├── project_data
│ │ │ ├── user_data
│ │ │ ├── validators
│ │ │ └── webhook_data
│ │ └── states
│ ├── infrastructure
│ │ ├── broker
│ │ └── database
│ ├── logic
│ │ ├── bot_logic
│ │ │ ├── filters
│ │ │ ├── handlers
│ │ │ │ ├── admins_handlers
│ │ │ │ ├── commons_handlers
│ │ │ │ ├── instructions_handlers
│ │ │ │ ├── profile_handlers
│ │ │ │ └── projects_handlers
│ │ │ ├── keyboards
│ │ │ └── middlewares
│ │ ├── services
│ │ └── web_app_logic
│ │ └── route_dependency
│ ├── presentation
│ │ ├── bot_routers
│ │ └── web_app_routes
│ └── utils
├── strings
└── testsКратко про пакеты:
config- содержит файл с конфигурацией дляDynaconf;core- содержит основной файл проектаapp.pyи файл конфигурацииsettings.py;entities- содержит пакеты с различными сущностями данных, используемых в проекте: классы коллбэков, перечисления, Pydantic-схемы и состояния;infrastructure- содержит логику подключения кMongoDBиRedis, а также методы по работе с ними;logic- содержит основную логику приложения:bot_logic- содержит логику Telegram-бота, также с разделением на логические блоки;services- содержит логику выполняемых процессов, например, чтобы не захламлять функцию-обработчик процессом получения данных, выносим весь процесс в отдельный метод;web_app_logic- содержит логикуFastAPI-приложения;
presentation- содержит описания маршрутов для бота и веб-приложения;utils- содержит разнообразные утилитарные функции, например, файл с инициализацией логгера или получением текста изYAML-файлов;strings- содержитYAML-файлы со всем используемым в приложении текстом, а также конфигурациями клавиатур;tests- содержит тесты приложения.
Такая структура позволяет чётко осознавать где находится то, что нужно.
Зависимости и необходимые инструменты
Перед тем как начать писать код самого проекта, необходимо установить библиотеки и добавить конфигурационные файлы.
Зависимости
Библиотеки в uv устанавливаются точно так же как и в poetry, а именно командо uv add.
На момент написания статьи в проекте используются следующие библиотеки:
- Основные зависимости:
aiogramверсии3.17.0;dynaconfверсии3.2.7;fastapiверсии0.115.8;motorверсии3.7.0;pydanticверсии2.10.6;pyyaml-includeверсии2.2;redisверсии5.2.1;uvicornверсии0.34.0.
- Dev зависимости:
blackверсии25.1.0;pre-commitверсии4.1.0;pytestверсии8.3.4;pytest-asyncioверсии0.25.3.
Подробнее рассказано в прошлой статье "Taigram: Начало работы".
Конфигурация Dynaconf
В проекте мы решили использовать библиотеку Dynaconf для создания файла с переменными конфигурации. Конечно, можно было бы обойтись простым .env, как это делают многие, но у него есть свои ограничения.
Когда проект маленький, .env вполне хватает — просто прописываешь переменные в файле, загружаешь их через python-dotenv или pydantic-settings, и все работает. Но чем больше настроек, тем сложнее с ними управляться: нужно помнить про разные среды (dev, prod, test), следить за типами данных, а если появляются вложенные структуры — начинается хаос.
Вот тут на сцену выходит Dynaconf. Он позволяет хранить конфигурацию не только в .env, но и в YAML, JSON, TOML, ini, а также разделять настройки по средам. Таким образом мы раз и навсегда решили проблему "дискомфорта" при переключении между уровнями разработки и обеспечения удобства для последующей поддержки кода.
Актуальный файл конфигурации выглядит следующим образом:
dynaconf_merge: true
default:
ADMIN_IDS:
- 1234556
WEBHOOK_PATH: "/webhook"
UPDATES_PATH: "/updates"
YAML_FILE_PATH: "strings"
LOG_DIR: "logs"
LOG_FILE: "logs.txt"
LOG_LEVEL: "INFO" # (DEBUG, INFO, WARNING, ERROR, CRITICAL)
MAX_SIZE_MB: 10
BACKUP_COUNT: 5
PRE_REGISTERED_LOGGERS: [ "uvicorn", "aiogram" ]
DEFAULT_LANGUAGE: "ru"
ALLOWED_LANGUAGES: [ "ru", "en" ]
ITEMS_PER_PAGE: 5
prod:
TELEGRAM_BOT_TOKEN: "1234"
DB_URL: "mongodb://twhn_user:twhn_password@mongo:27017"
DB_NAME: "taigram"
REDIS_URL: "redis://redis:6379/0"
REDIS_MAX_CONNECTIONS: 20
WEBHOOK_DOMAIN: "https://example.com"
dev:
TELEGRAM_BOT_TOKEN: "1234"
DB_URL: "mongodb://twhn_user:twhn_password@localhost:27019"
DB_NAME: "taigram"
REDIS_URL: "redis://localhost:6379/0"
REDIS_MAX_CONNECTIONS: 20
test:
TELEGRAM_BOT_TOKEN: "1234"
DB_URL: "mongodb://twhn_user:twhn_password@localhost:27019"
DB_NAME: "taigram_test"
REDIS_URL: "redis://localhost:6379/10"
REDIS_MAX_CONNECTIONS: 20
YAML_FILE_PATH: "tests/fixtures/strings"
LOG_DIR: "tests/fixtures/logs"
LOG_FILE: "logs.txt"
LOG_LEVEL: "INFO"Как видим, конфигураций у приложения не мало, и что немаловажно, еесть разделения по используемым окружениям. Выбор осуществляется переменной окружения ENV_FOR_DYNACONF, значение которой подключает указанный блок, а блок default работает во всех окружениях.
.env-файл
Как бы не был хорош Dynaconf, избавиться от .env-файла не получится, поскольку значения указанные в нём используются в docker-compose.yaml (о котором дальше).
На данный момент там всего две переменные:
MONGO_USERNAME=twhn_user
MONGO_PASSWORD=twhn_passwordОни нужны для создания контейнера с MongoDB.
docker-compose.dev.yaml
Мы сразу создали Docker Compose файл, но если вы обратите внимание, в его названии есть .dev. Это указывает на то, что данный композ-файл предназначен для процесса разработки, а не продакшена.
По сути, это самый обычный композ файл, в котором указаны сервисы MongoDB и Redis с открытыми портами. В нём не указана сборка проекта, т.к. во время разработки проект запускается локально, но ему всё равно нужна база данных и брокер.
Актуальный docker-compose.dev.yaml выглядит так:
services:
mongo:
image: mongo
container_name: twhn_mongo
restart: always
environment:
MONGO_INITDB_ROOT_USERNAME: ${MONGO_USERNAME}
MONGO_INITDB_ROOT_PASSWORD: ${MONGO_PASSWORD}
volumes:
- twhn_mongo_db:/data/db
ports:
- "27019:27017"
healthcheck:
test: [ "CMD","mongo", "--eval", "db.adminCommand('ping')" ]
interval: 10s
timeout: 10s
retries: 5
redis:
image: redis
restart: always
container_name: twhn_redis
volumes:
- twhn_redis_db:/data
ports:
- "6379:6379"
healthcheck:
test: [ "CMD-SHELL", "redis-cli", "ping" ]
interval: 10s
timeout: 5s
retries: 3
volumes:
twhn_mongo_db:
twhn_redis_db:Оба сервиса будут автоматически перезапускаться в случае падения, к ним подключены соответствующие Docker Volume для сохранения данных, а также указаны блоки healthcheck, которые сыграют важную роль в полноценном docker-compose.yaml.
pre-commit и PyTest в CI Workflow
Поскольку Taigram - это Open Source проект, то подразумевается, что в последствии к разработке могут присоединяться сторонние разработчики, а следовательно нам необходимо позаботиться о создании "правил единообразия".
Для того, чтобы обеспечить одинаковый "стиль кода" во всём проекте, а также избежать неиспользуемых импортов и прочих ошибок, мы подключили pre-commit. Он работает локально при отправке push'а в репозиторий, но его можно и "заглушить", при желании.
Тестируем код при помощи PyTest. Он также работает локально, но при пуше можно забыть прогнать тесты.
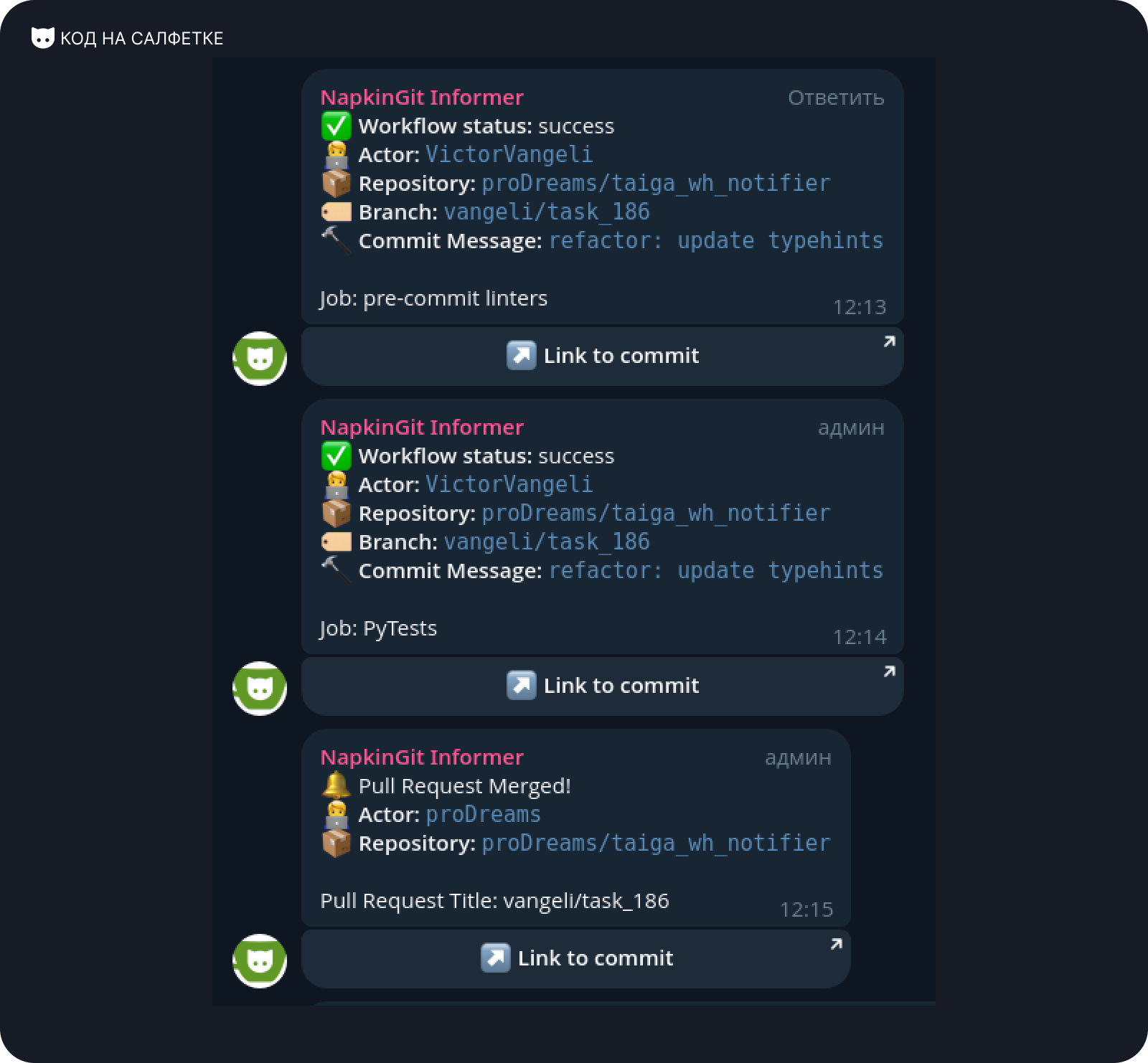
Чтобы убедиться "наверняка", что отправляемые изменения не содержат ошибок или расхождений в стиле, мы добавили CI Workflow, который при каждом пуше в репозиторий запускает действие, прогоняющее линтеры в pre-commit и тесты в `PyTest.
Поскольку проект располагается на GitHub, используем для этого GitHub Actions.
Скрипт Workflow:
name: Lint and Test Project
on:
push:
branches-ignore:
- main
jobs:
lint:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: "3.12"
- name: Cache Python dependencies
id: cache-python-deps
uses: actions/cache@v4
with:
path: |
.venv
~/.cache/uv
key: ${{ runner.os }}-python-deps-${{ hashFiles('uv.lock') }}
restore-keys: |
${{ runner.os }}-python-deps-
- name: Cache pre-commit hooks
id: cache-pre-commit
uses: actions/cache@v4
with:
path: ~/.cache/pre-commit
key: ${{ runner.os }}-pre-commit-${{ hashFiles('.pre-commit-config.yaml') }}
restore-keys: |
${{ runner.os }}-pre-commit-
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install uv
uv sync
uv run pre-commit install
- name: Lint pre-commit
run: uv run pre-commit run --all-files --hook-stage manual
- name: Run Telegram Notify Action
uses: proDreams/actions-telegram-notifier@main
if: always()
with:
token: ${{ secrets.TELEGRAM_BOT_TOKEN }}
chat_id: ${{ secrets.TELEGRAM_CHAT_ID }}
thread_id: ${{ secrets.TELEGRAM_THREAD_ID }}
status: ${{ job.status }}
notify_fields: "actor,repository,branch,commit"
message: "Job: pre-commit linters"
test:
runs-on: ubuntu-latest
needs: lint
services:
redis:
image: redis:latest
ports:
- 6379:6379
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: "3.12"
- name: Cache Python dependencies
id: cache-python-deps
uses: actions/cache@v4
with:
path: |
.venv
~/.cache/uv
key: ${{ runner.os }}-python-deps-${{ hashFiles('uv.lock') }}
restore-keys: |
${{ runner.os }}-python-deps-
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install uv
uv sync
- name: Create settings.yaml
run: mv config/settings.yaml.example config/settings.yaml
- name: Run PyTest
env:
ENV_FOR_DYNACONF: test
TELEGRAM_BOT_TOKEN: ${{ secrets.TELEGRAM_BOT_TOKEN }}
run: uv run pytest
- name: Run Telegram Notify Action
uses: proDreams/actions-telegram-notifier@main
if: always()
with:
token: ${{ secrets.TELEGRAM_BOT_TOKEN }}
chat_id: ${{ secrets.TELEGRAM_CHAT_ID }}
thread_id: ${{ secrets.TELEGRAM_THREAD_ID }}
status: ${{ job.status }}
notify_fields: "actor,repository,branch,commit"
message: "Job: PyTests"У нас есть две независимые задачи:
lint- запускает линтеры вpre-commit;test- запускает тесты вPyTest.
Оба сценария примерно похожи:
- Настраиваем
Python; - Проверяем наличие сохранённого кэша;
- Устанавливаем зависимости;
- Выполняем действие;
- Не зависимо от результата, отправляем оповещение в Telegram-чат при помощи actions-telegram-notifier.
Singletone: глобальная точка входа
Для того, чтобы реализовать заложенный потенциал dynaconf и быть готовыми к масштабированию кода - перед нами встала задача: как инициализировать различные компоненты, чтобы это было:
1. Удобно:
Singleton позволяет:
- Иметь один экземпляр конфигурации, который инициализируется один раз и используется повсеместно.
- Избежать повторной загрузки настроек, что экономит ресурсы.
- Упростить доступ к конфигурации через глобальную точку (например,
Config.strings()
Это удобно, потому что любой модуль может получить доступ к конфигурации без необходимости передавать объект конфигурации через параметры или создавать его заново. Это уместно, если архитектура предполагает, что конфигурация неизменна или редко меняется в рамках выполнения приложения.
2. Понятно:
Когда вся команда знает, что конфигурация доступна через Config.strings(), это становится прозрачным и предсказуемым интерфейсом. Нет необходимости гадать, где и как создаётся объект конфигурации — всё централизовано.
Кроме того, использование Singleton делает код более декларативным: вместо того чтобы в каждом модуле прописывать логику загрузки конфигурации, мы просто обращаемся к готовому объекту.
Это понятно, потому что паттерн Singleton широко известен и легко воспринимается разработчиками. Если в документации или коде указано, что конфигурация доступна через Singleton, это снижает порог входа для новых членов команды.
3. Подготовка к масштабированию (не стыдно)
При масштабировании приложения важно, чтобы архитектура не создавала узких мест и позволяла легко добавлять новые модули. Singleton помогает:
- Гарантировать, что все модули используют одну и ту же конфигурацию, что исключает рассинхронизацию.
- Централизовать управление конфигурацией, что упрощает её обновление или переключение (например, между окружениями: dev, prod).
- Избежать лишних затрат на инициализацию, что важно при большом количестве модулей.
Решение выглядит "не стыдно", потому что оно продуманное и учитывает будущие потребности. Например, если в будущем потребуется добавить кэширование конфигурации или динамическое обновление настроек, Singleton может быть расширен без серьёзных изменений в архитектуре.
На наш взгляд Singltone справляется со всеми поставленными задачами.
Утилита чтения YAML-файлов и утилита логгера
Одним из первоначального кода у нас были утилитарные функции, которые потребуются почти в самом начале, поэтому начали с них.
yaml_utils.py
Поскольку бот для взаимодействия с пользователем в основном использует текст, то и текста будет не мало, особенно, учитывая, что мы решили сразу реализовать мультиязычность. Хардкодить текст внутри кода очень плахая и не гибкая идея, а использовать библиотеки I*n тоже казалось неудобным в нашей реализации.
Самым удобным вариантом оказалось использование YAML-файлов с текстом.
Для этого была написана небольшая утилита:
def get_strings(path: str) -> dict[str, str | dict[str, str | list]]:
strings_dict = {}
for path in Path(path).glob("*.yaml"):
with open(path, encoding="utf-8") as f:
strings_dict.update({path.stem: dict(yaml.safe_load(f))})
return strings_dictСуть в том, что она читает все *.yaml-файлы в указанной директории и собирает в один большой словарь. Это очень удобно.
Однако, спустя время нас посетила одна идея - "подключать" внутри файла другой файл для того, чтобы упростить сборку некоторых конфигураций. Для этого понадобилась библиотека pyyaml_include.
Изменённый код утилиты:
from pathlib import Path
import yaml
import yaml_include
def process_references(data) -> None:
if "buttons" not in data:
return
buttons = data["buttons"]
for section, section_data in data.items():
if section != "buttons" and isinstance(section_data, dict):
buttons_list = section_data.get("buttons_list")
if buttons_list:
for i, row in enumerate(buttons_list):
for j, item in enumerate(row):
if isinstance(item, dict) and "ref" in item:
ref = item["ref"]
if ref in buttons:
button_def = buttons[ref].copy()
button_def.update({k: v for k, v in item.items() if k != "ref"})
buttons_list[i][j] = button_def
data.pop("buttons")
def generate_strings_dict(path: str) -> dict[str, dict | list | str]:
yaml.add_constructor("!include", yaml_include.Constructor(base_dir=path))
strings_dict = {}
for file_path in Path(path).glob("*.yaml"):
with open(file_path, encoding="utf-8") as f:
data = yaml.full_load(f)
strings_dict[file_path.stem] = data
process_references(data)
return strings_dictКода стало больше и он стал сложнее, но он запускается всего раз при запуске приложения, а затем мы работаем с данными в памяти.
Таким образом мы смогли проворачивать вот такие конструкции:
# keyboard_buttons.yaml
get_main_menu:
text: get_main_menu
callback_class: MenuData
# static_keyboards.yaml
buttons: !include keyboard_buttons.yaml
start_keyboard:
buttons_list:
- - ref: get_main_menu
keyboard_type: "inline"logger_utils.py
Неотъемлемой частью является логирование, но вот незадача - у aiogram один вид лога, у uvicorn другой, а у встроенного Logger третий. Нужно было стандартизировать формат логирования во всех компонентах, а также настроить сохранение логов в файл.
Для этого мы написали класс LoggerUtils основанный на паттерне Singleton. Singleton позволит нам иметь одновременно только один экземпляр класса.
Код логгера:
import logging
from logging.handlers import RotatingFileHandler
from pathlib import Path
import dynaconf
from src.core.Base.singleton import Singleton
class LoggerUtils(Singleton):
def __init__(self, settings: dynaconf.Dynaconf):
self.log_dir = Path(settings.LOG_DIR)
self.log_file = self.log_dir / settings.LOG_FILE
self.log_level = settings.LOG_LEVEL
self.max_log_size = settings.MAX_SIZE_MB
self.backup_count = settings.BACKUP_COUNT
self.pre_registered_loggers = settings.PRE_REGISTERED_LOGGERS
self._setup_logging_directory()
for logger_name in self.pre_registered_loggers:
self.get_logger(logger_name)
def _setup_logging_directory(self):
self.log_dir.mkdir(parents=True, exist_ok=True)
def _get_console_handler(self) -> logging.Handler:
console_handler = logging.StreamHandler()
console_handler.setLevel(self.log_level)
console_handler.setFormatter(self.get_log_formatter())
return console_handler
def _get_file_handler(self) -> logging.Handler:
file_handler = RotatingFileHandler(
filename=self.log_file,
encoding="utf-8",
maxBytes=self.max_log_size * 1024 * 1024,
backupCount=self.backup_count,
)
file_handler.setLevel(self.log_level)
file_handler.setFormatter(self.get_log_formatter())
return file_handler
@staticmethod
def get_log_formatter() -> logging.Formatter:
return logging.Formatter(
fmt="[%(asctime)-25s][%(levelname)-8s][%(name)-20s]"
"[%(filename)-15s][%(funcName)-25s][%(lineno)-4d][%(message)s]"
)
def get_logger(self, name: str | None = None) -> logging.Logger:
logger = logging.getLogger(name)
if not logger.hasHandlers():
logger.setLevel(self.log_level)
logger.addHandler(self._get_console_handler())
logger.addHandler(self._get_file_handler())
return loggerПрочие текстовые утилиты:
В последствии у нас появились дополнительные методы, например:
- утилита, позволяющая форматировать строку в формате YAML с использованием переданных именованных аргументов (
kwargs), чтобы вместо "Hello, world! My name is {user_name}", получить строку "Hello, world! My name is Petr."; - утилиты, позволяющие получать текст сообщения/кнопки, в соответствии с выбранным языком в системе у пользователя;
Об этих утилитах мы расскажем подробнее в следующих статьях, но не упомянуть их сейчас, к сожалению не можем.
Заключение
К настоящему моменту мы несколько раз кардинально перерабатывали модули и пакеты, чтобы оптимизировать ряд процессов, поэтому контента для рубрики накопилось достаточно.
В следующих статьях мы расскажем о:
- процессе создания pydantic схем и анализу веб-хуков
Taiga; - универсальной клавиатуре для Telegram бота и почему мы пришли к выводу о необходимости собственной надстройки;
- создании CRUD для Mongo DB;
Мы были бы рады, если бы вы в комментариях поделились своими впечатлениями или рассказали, что на ваш взгляд можно было бы улучшить.
Также было бы приятно, если бы вы положительно оценили эту статью.
Ссылки, касающиеся проекта:

Комментарии