![[НЕ]Вайбкодим анализатор страниц на FastAPI](/media/post/2025/05/15/AI_exp_1.png)
Введение
Приветствую!
В нашем чате "Кот на салфетке" (кстати, заходите — у нас весело) регулярно всплывают бугурты об использовании различных ИИ-агентов (Copilot, Cursor) для написания кода. Главными инициаторами сего действа выступают Сергей и Кавай (расскажите маме, что вы в "тиливизаре").
Они оба проповедуют диаметрально противоположные позиции:
- Серёже интересно пробовать новое, искать обходные пути для решения рутинных задач и просто экспериментировать.
- В свою очередь Кавай не приемлет использование ИИ-агентов , предпочитая вести разработку самостоятельно.
Этот спор "бобра с ослом" (просто фраза) перерос в такой сюр, что его нельзя было игнорировать. Мне стало интересно, так ли хороши "эти ваши агенты" или всё же это "хайп" на пустом месте?
С этой ноты запускаю новую (и нерегулярную) рубрику — «Эксперименты с ИИ». В ней я буду пробовать писать разные проекты, используя только ИИ-агентов, а затем разбираться, что у них получилось.
Почему нерегулярную, спросите вы? Всё просто: для таких экспериментов нужны и идеи, и — что немаловажно — ваша активность. Если рубрика вам зайдёт, и вы начнёте предлагать интересные темы, буду продолжать!
Моё мнение
Его вполне можно назвать предвзятым — но на то оно и моё. Я считаю, что ИИ — это отличные помощники или инструменты. Они помогают что-то объяснить, подсказать, направить, когда застрял. Раньше мы для этого шли на Stack Overflow, теперь проще и быстрее спросить у ИИ — и часто получить даже более развёрнутый ответ.
Но важно помнить: как ни крути, ИИ регулярно ошибается. То он возьмёт устаревшую библиотеку, то придумает что-то несуществующее, проще говоря, начнёт "галлюцинировать". В общем, классика: доверяй, но проверяй.
А вот идея использовать агентов для написания кода целиком за меня — мне не близка. И вот почему:
- Нет контроля над происходящим. Да, можно пытаться управлять промптами, следить за тем, что он пишет, но этого недостаточно. Если возникают ошибки, их не всегда просто заметить сразу — и часто они всплывают слишком поздно. Спойлер: так оно и будет.
- Время. Как бы парадоксально это ни звучало, на работу с агентом уходит больше времени, чем если бы я писал сам. Потому что весь сгенерированный код нужно прочитать, понять, почти всегда — доработать. Я не беру в расчёт так называемых "вайб-кодеров", которые гордо заявляют: «Я не знаю программирования, но написал программу!» — здесь мы рассматриваем ИИ как помощника для программиста.
- Качество кода и архитектура. Чаще всего ИИ пишет код посредственного качества, а местами — откровенный "спагетти". Про архитектуру он, кажется, вообще не слышал. Всё либо валится в один
main.py, либо с минимальным делением на файлы и без какой-либо структуры.
Правила рубрики
Поскольку это пилотный выпуск рубрики, правила пока временные. Буду дорабатывать их по ходу дела — с учётом ваших комментариев и предложений.
- Старт с нуля
Работа начинается с полностью пустой директории — никаких предварительных файлов или заготовок, если задача не требует иного, например, продолжение предыдущего проекта или за основу взят уже написанный код. - Инструменты разработки
Используется VSCode как основная IDE.
Комментарий: PyCharm не применяется, так как ограничивает взаимодействие с агентами без платного плагина. - Взаимодействие с ИИ
Все промпты пишутся максимально подробно:
• описывается структура проекта,
• список необходимых библиотек,
• логика компонентов,
• предполагаемое поведение.
В качестве ИИ-помощника используется GitHub Copilot с ChatGPT 4.1 Preview. В следующих экспериментах, возможно, буду пробовать и другие агенты. например, Cursor или CLINE. - Никаких ручных правок кода
Полученный от ИИ код не редактируется вручную до момента целенаправленного разбора/анализа. - Учёт взаимодействий
На текущем этапе не вводится лимит на количество запросов к ИИ. Однако будет вестись учёт количества промптов до получения работоспособной версии проекта.
Цель сегодняшнего эксперимента
Как вы уже догадались из названия статьи, сегодня мы будем делать API анализатора страниц на FastAPI.
Идея не пришла ко мне сама собой, её я позаимствовал (и даже не спросил разрешения, негодяй!) у другого автора "салфетки". Виктор сейчас заканчивает обучение на курсах и один из проектов был сделать как раз такой анализатор страниц. Ну, как такой, более продвинутый в технологическом плане: с БД, и маршрутов побольше, но на Flask.
Я видел его решение и оно бесспорно достойное (не смотря на то, что используется Flask), но я решил для эксперимента не усложнять задачу, а взять основу идеи.
Простое API с двумя маршрутами:
/analyze-page- Метод:
POST - Тело запроса (JSON):
page— ссылка для анализа
- Что делает:
- Получает ссылку, проверяет её и возвращает результат анализа
- Метод:
/analyze-history- Метод:
GET - Что делает:
- Возвращает 10 последних проверок
- Метод:
Используемые технологии:
Python >=3.12FastAPI >=0.115
Что именно будем анализировать на странице:
- Статус ответа
- Заголовок страницы (
<title>) - Описание (
<meta name="description">) - Содержимое первого тега
<h1>
Где будем хранить историю запросов:
- В оперативной памяти
Задача простая — посмотрим, как с ней справится ИИ.
Критерии приёмки
Чтобы, так сказать, добавить "академичности" в этот эксперимент — обозначу критерии приёмки результата.
Функциональная полнота
Цель: Проверить, соответствует ли готовый проект техническому заданию.
Выполнение базовых требований:
- Реализованы два маршрута (
/analyze-pageи/analyze-history). - Анализ страницы включает: статус-код,
<title>,<meta description>, первый<h1>. - Сохранение истории (максимум 10 записей).
Обработка ошибок: - Корректная валидация URL (формат, доступность).
- Обработка таймаутов и ошибок сервера (5xx).
Качество кода
Цель: Проверить, насколько код соответствует стандартам читаемости, поддерживаемости и современным практикам.
Чистота и структура:
- Разделение на модули.
- Использование Pydantic-моделей.
Стиль кода: - Соответствие PEP 8 (или другим стандартам).
- Наличие комментариев/документации в сложных частях.
Использование современных инструментов: - Python 3.12+, FastAPI, Poetry, Makefile.
Архитектурные решения
Цель: Оценить, насколько ИИ продумал структуру проекта и соблюдал принципы проектирования.
Разделение ответственности:
- Логика маршрутов, анализа страницы и работы с историей вынесены в отдельные модули.
- Использование исключений вместо «голых» ошибок.
Масштабируемость: - Возможность расширения (например, добавление БД).
Документация и инструкции
Цель: Проверить, насколько проект готов к использованию другими разработчиками.
README.md:
- Описание функционала, инструкция по запуску, примеры запросов.
Makefile: - Команды инициализации и запуска
Докстринги и аннотации: - Докстринги к функциям с описанием логики и аргументов.
- Аннотация типов.
Эффективность и время
Цель: Оценить, насколько ИИ оптимизировал процесс разработки.
Временные затраты:
- Написание промпта.
- Взаимодействие с ИИ.
- Анализ результата.
Приступаем к эксперименту
Для начала подготовлю первый промпт — с максимально полной информацией для агента.
Почему важно составлять промпт подробно?
Многие привыкли писать промпты в стиле: «сделай то», «сделай это», «а как ...?» — и только к пятому (и более) запросу получают то, что нужно, постоянно добавляя конкретику. При этом они засоряют контекст лишними промежуточными вариантами.
Чтобы получить максимально близкий к нужному результат, ИИ нужно дать как можно больше информации:
- Указать используемый стек: язык, библиотеки, их версии.
- Подробно описать проблему или задачу.
- Привести примеры существующего кода — не только самого запроса, но и сопутствующего. Например, если просишь помочь с CRUD, нужно показать и модель, и пример существующего CRUD с входными данными.
Почти всё необходимое я уже описал в прошлом блоке, так что используем это как основу для запроса:
Создай FastAPI-приложение на Python 3.12, реализующее API для анализа веб-страниц.
Требования:
1. Маршруты:
- POST /analyze-page:
- Принимает JSON с параметром page (URL для анализа)
- Валидирует URL (корректный формат и доступность)
- Возвращает JSON с:
- статусом ответа страницы
- текстом тега <title>
- содержимым <meta name="description">
- первым <h1> на странице
- Сохраняет результат в памяти (максимум 10 последних запросов)
- GET /analyze-history:
- Возвращает JSON-массив 10 последних анализов.
2. Технологии:
- Используй Python 3.12 или выше (доступен в системе)
- Используй Poetry для управления зависимостями
- Используй Makefile для создания команд запуска
- FastAPI >=0.115 с Pydantic моделями для запросов/ответов
- Используй асинхронный HTTPX для HTTP-запросов и beautifulsoup4 для парсинга HTML
- Хранение данных в памяти (например, через глобальный список с ограничением длины)
3. Обработка ошибок:
- Кастомные HTTP-исключения для:
- Некорректного URL (422)
- Недоступности страницы (например, 5xx ошибки сервера)
- Таймаута запроса (например, 10 секунд)
4. Архитектура:
- Исходный код в директории src
- Разбивай всё на логичные модули. Например, маршруты, логика выполняема в маршруте, утилиты, схемы - это всё в рахных файлах и даже пакетах.
- Должен быть файл с точкой входа в приложение
- В маршрутах используй роутер
5. Дополнительно:
- Добавь CORS middleware
- Оформи README.md с инструкцией по запуску проекта и примерами запросовВот такой вышел промпт. Отправляю его агенту.
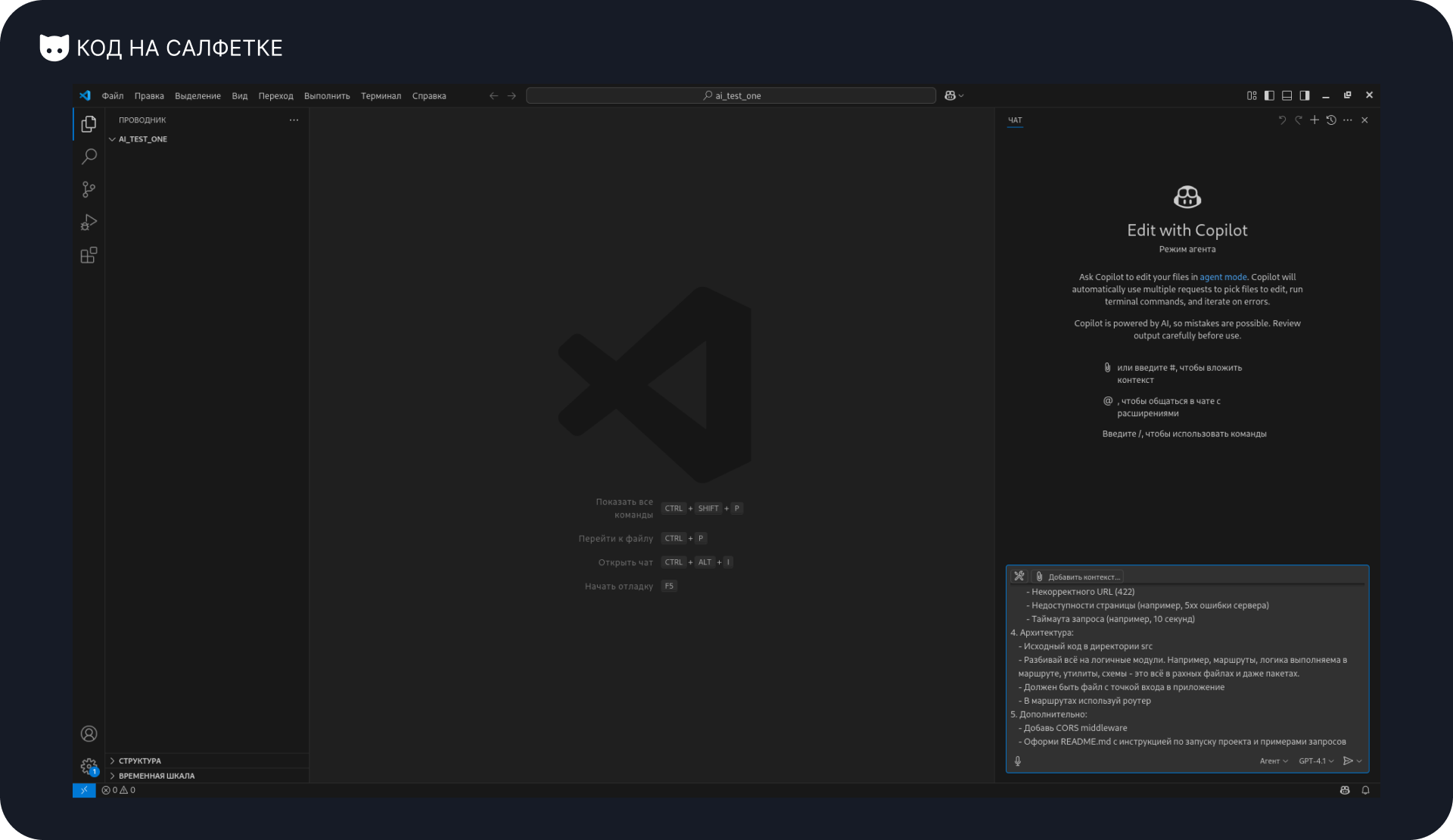
Вот что ответил агент:
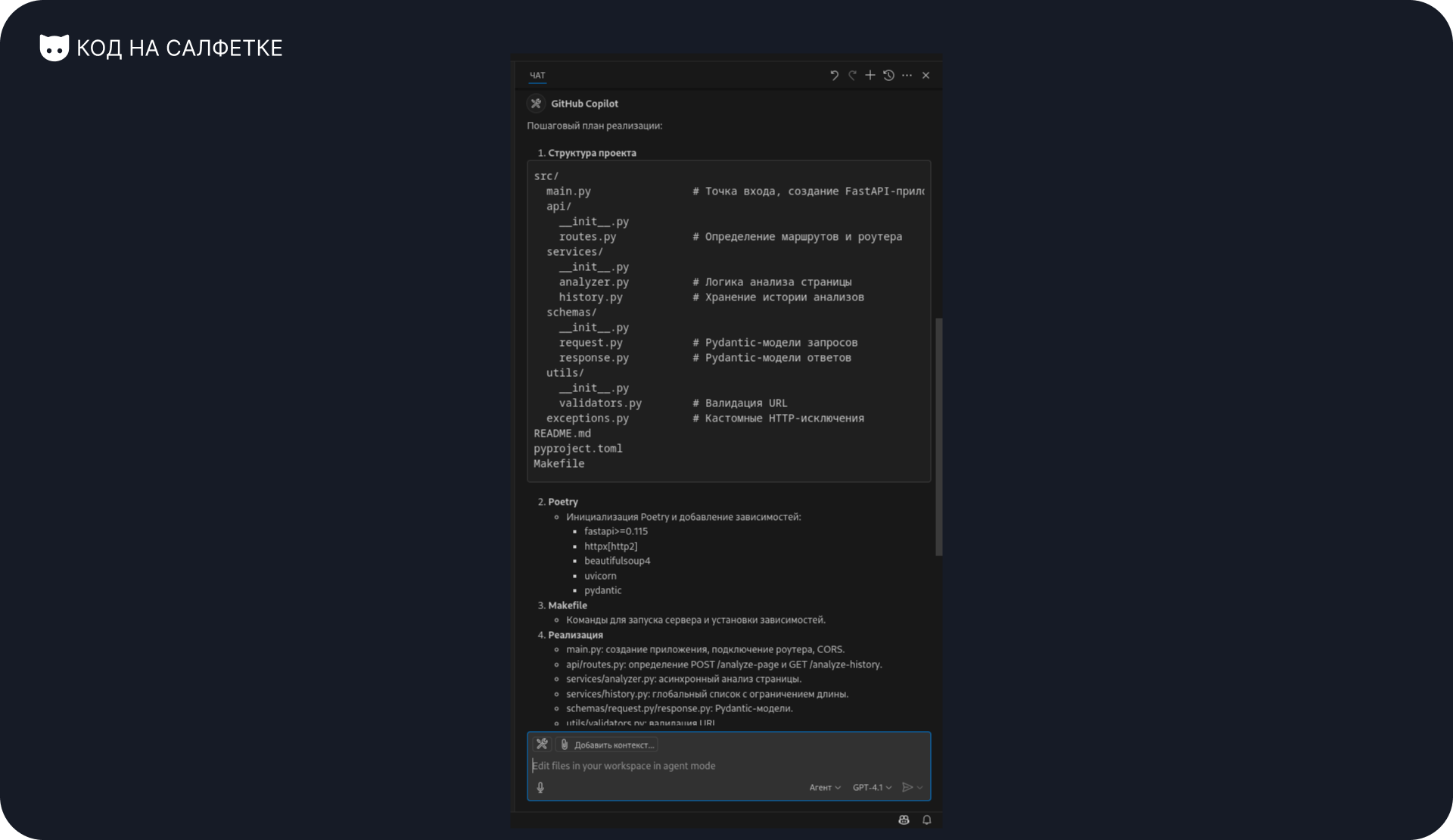
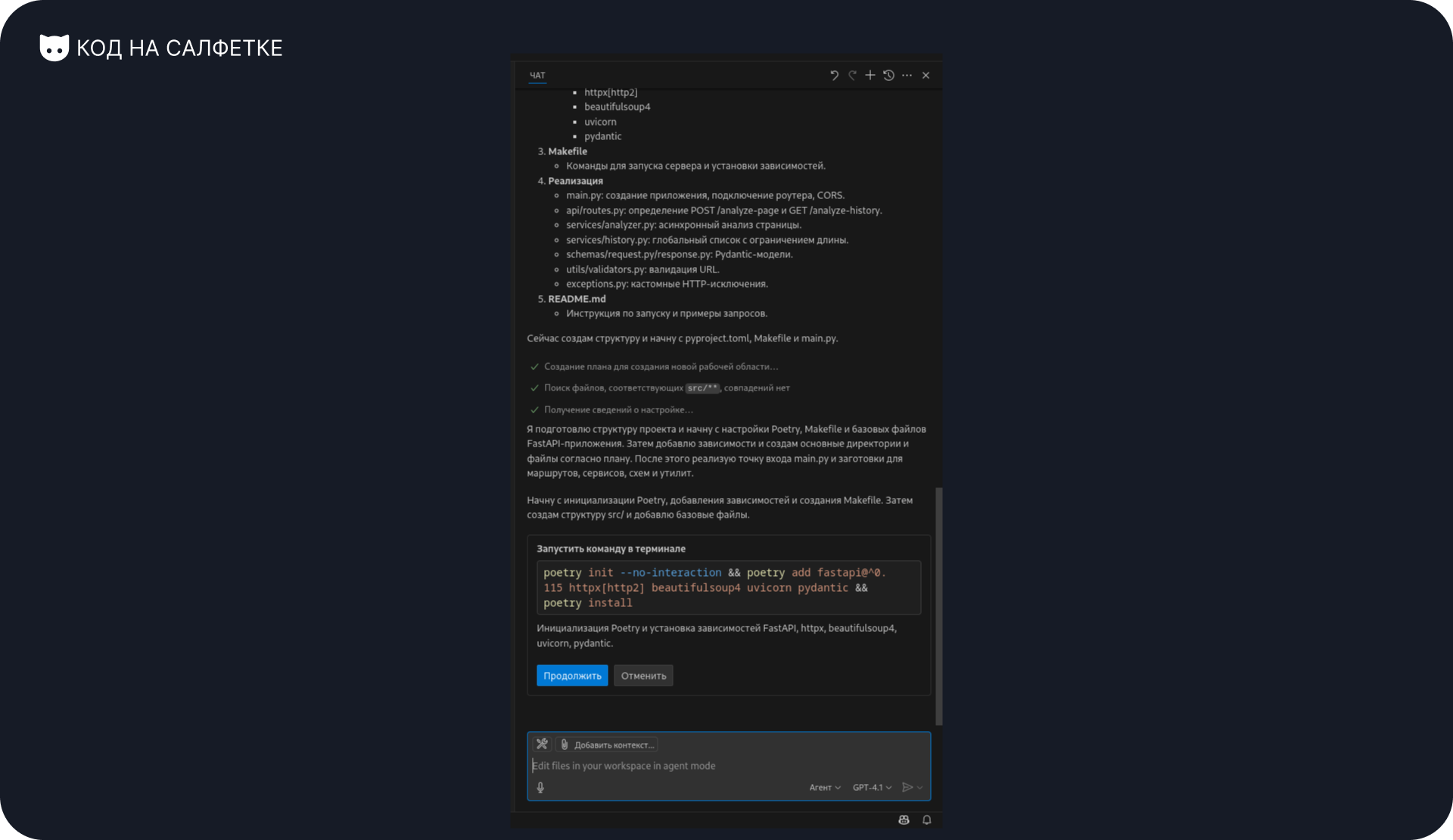
Он подготовил план и предложил выполнить команду в терминале для инициализации проекта. Но в этой команде есть проблема — она не сработает.
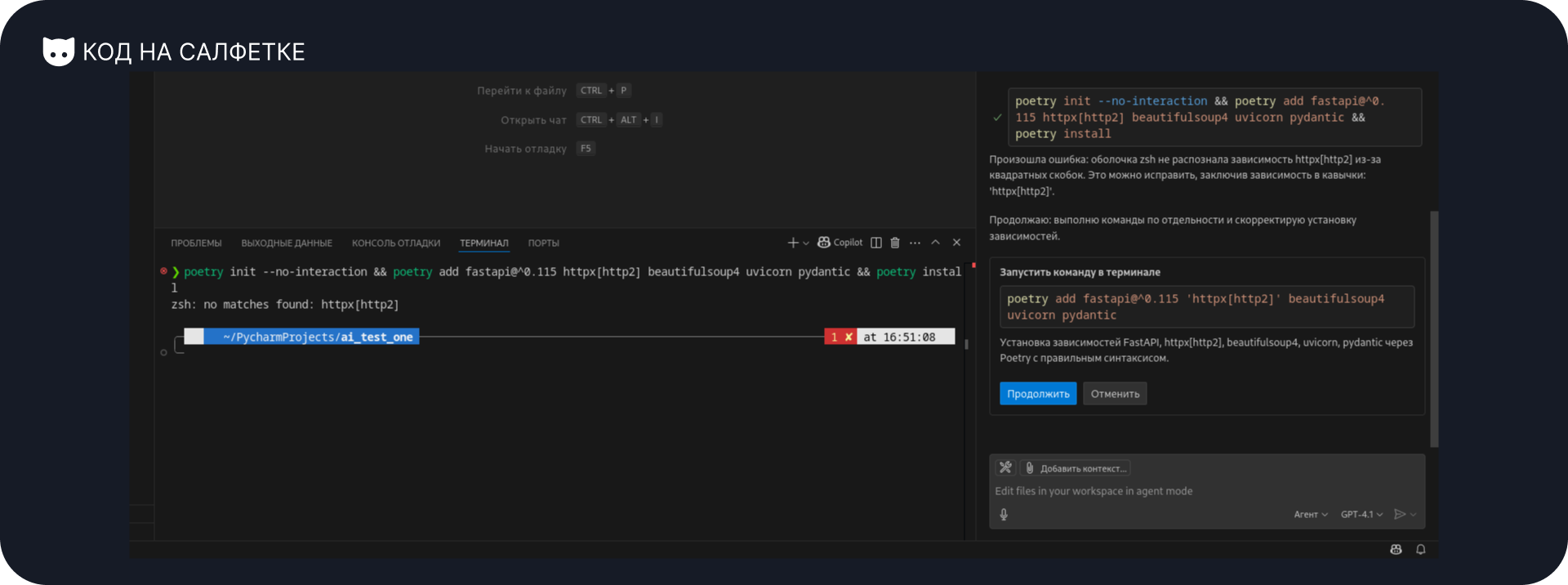
Так и произошло. Всё дело в том, что я использую zsh в качестве оболочки терминала. zsh не принимает команды вида что-то[...], ему нужно обязательно оборачивать это в кавычки. Тут нет ошибки агента, поскольку он дал команду для Bash, т.е. которая сработает у большинства, а я просто забыл уточнить этот момент. Однако, агент заметил ошибку и предложил исправленный вариант команды. Продолжаю.
Установка зависимостей и инициализация проекта прошли успешно. Теперь агент предлагает создать директории и заготовки файлов. Продолжаю.
Файлы успешно созданы. Ещё несколько заготовок — продолжаю.
Затем система агента уточняет, продолжать ли или приостановить выполнение. Это такая "защита" от сбоев или ошибок, если что-то пошло не по плану. Поскольку всё идёт хорошо, продолжаю.
Агент переходит к заполнению файлов в ударном темпе. Пока ничего не трогаю, просто продолжаю.
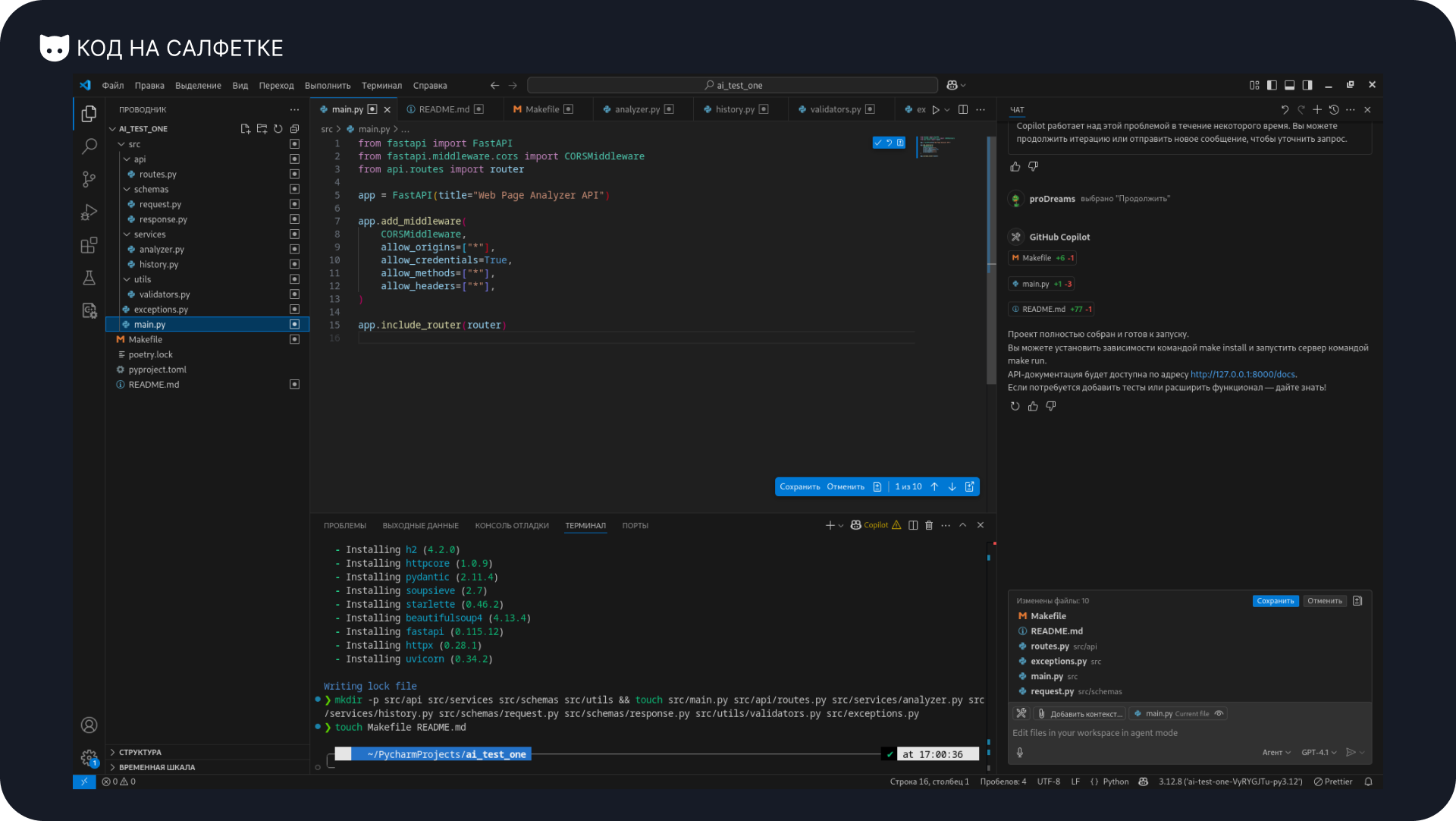
Он сообщает, что всё готово и можно проверять.
Запуск проекта
Итак, что же такого написал ИИ-агент? В код пока не заглядываю — пусть будет сюрпризом.
Сейчас главное — проверить, запускается ли проект. Для этого в терминале выполняю команду make run.
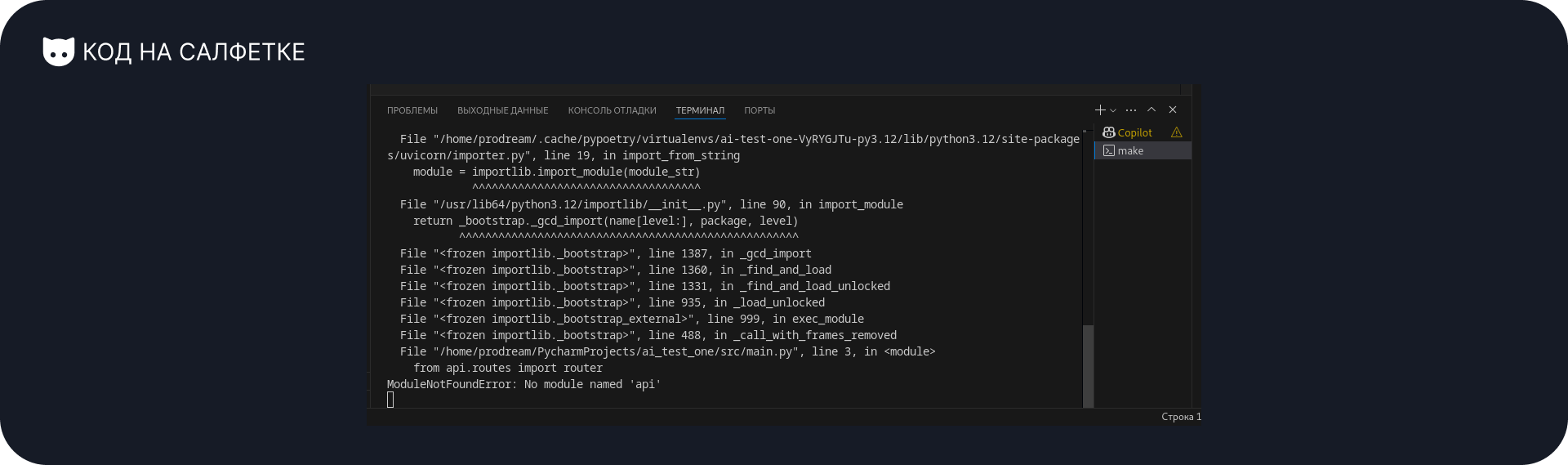
Что-то пошло не так. Наверняка вы тоже догадались, в чём проблема по трейсбэку. Но, следуя своему правилу «не правлю код руками», иду к агенту — пусть сам разбирается со своим косяком.
Копирую всё из терминала и отправляю ему. Надеюсь, найдёт решение быстро.
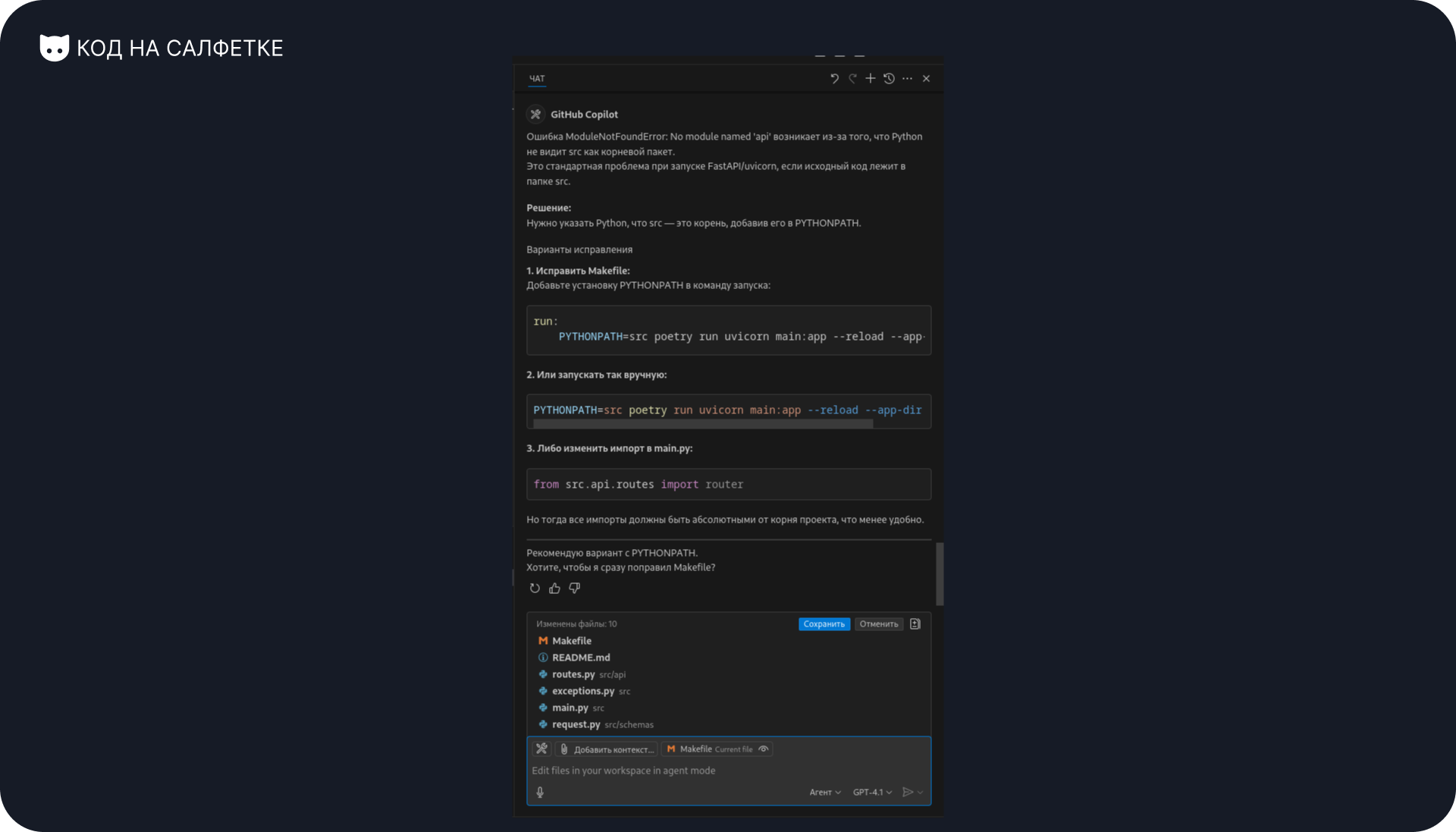
Он предлагает два варианта:
- Добавлять переменную окружения
PYTHONPATH=srcпри запуске. - Заменить все импорты на абсолютные относительно директории
src.
Первый вариант — костыль. Второй — выглядит куда лучше. Пишу агенту:
Третий вариант с абсолютными импортами мне нравится больше, примени во всём проекте, чтобы не было проблем с ненайденным модулем.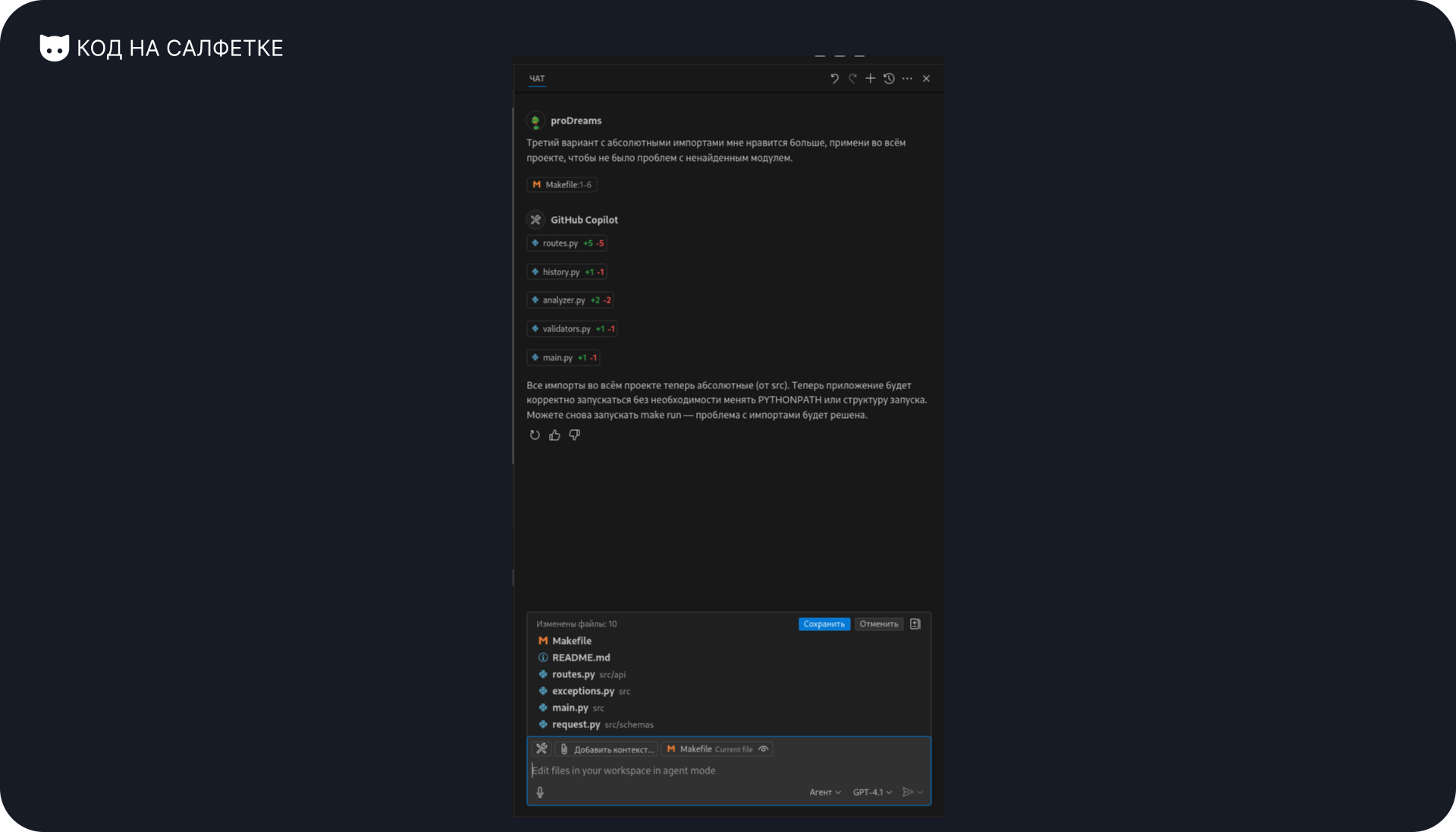
Агент говорит, что всё поправил. Проверяю.

И действительно — сервер запустился без ошибок. Открываю Swagger-документацию:
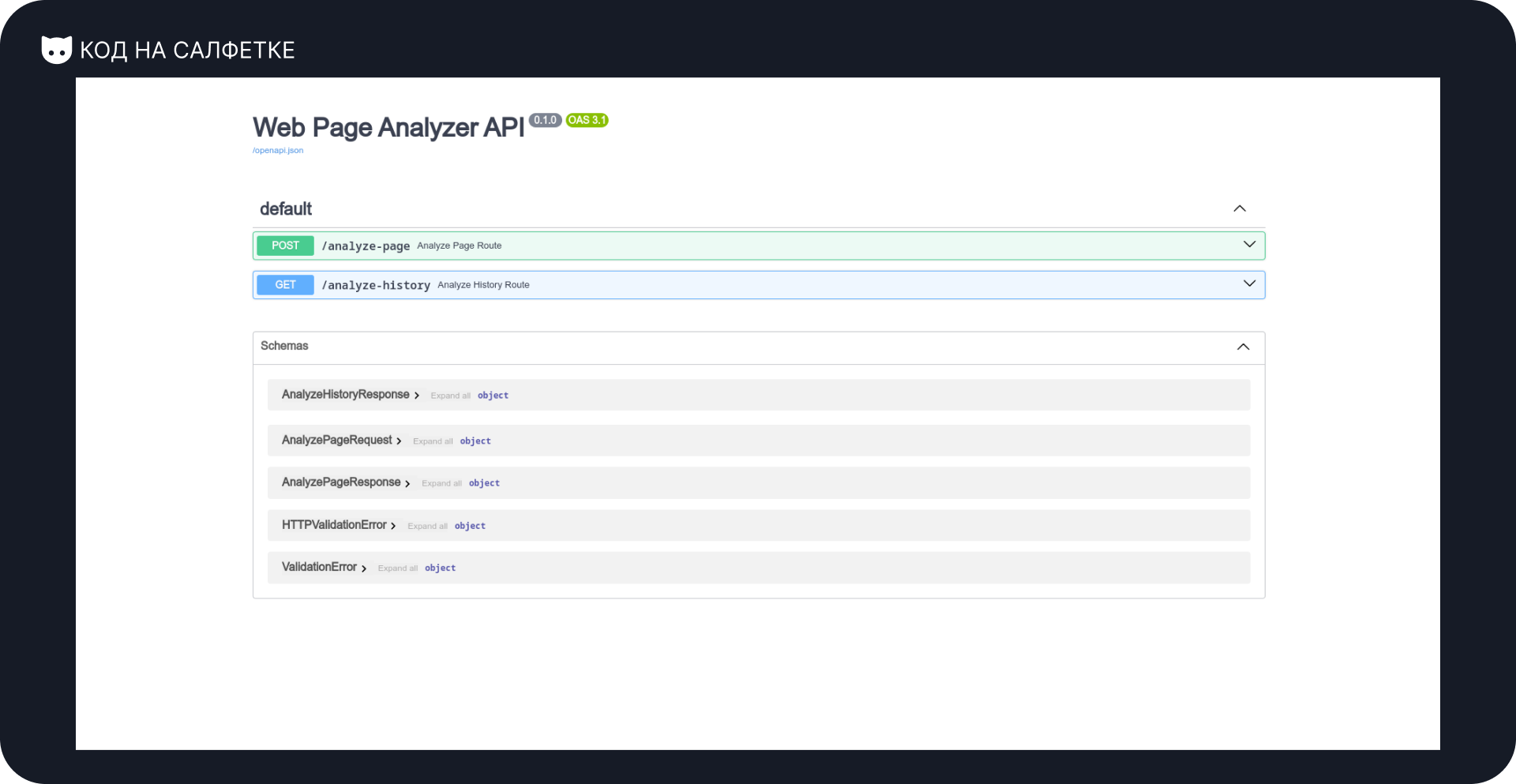
Проверка анализатора страниц
Пора проверить, как агент справился с основной задачей — анализом страницы.
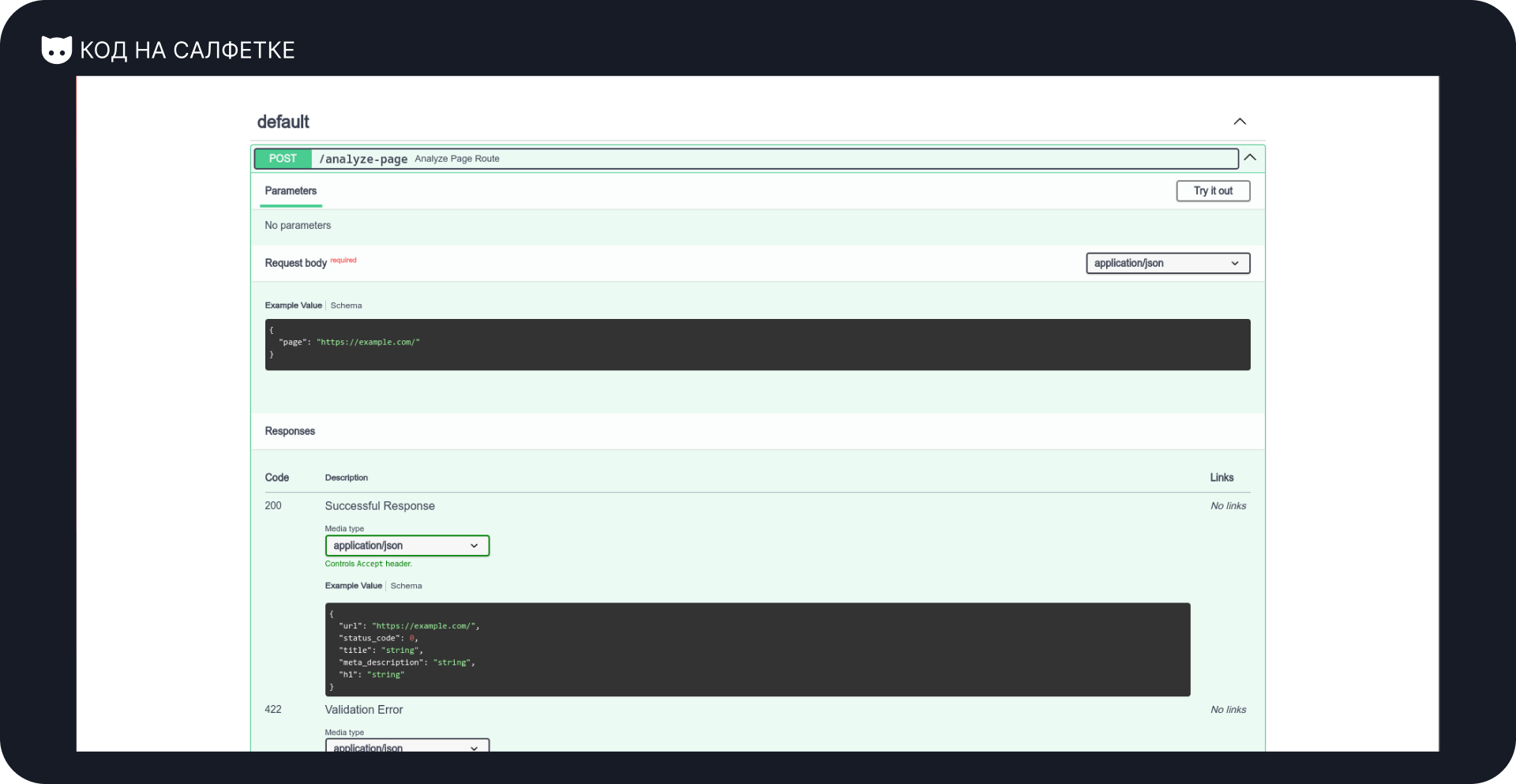
Всё по плану: отправляем ссылку — получаем информацию.
Для теста выбрал главную страницу проекта «Код на салфетке»: https://pressanybutton.ru
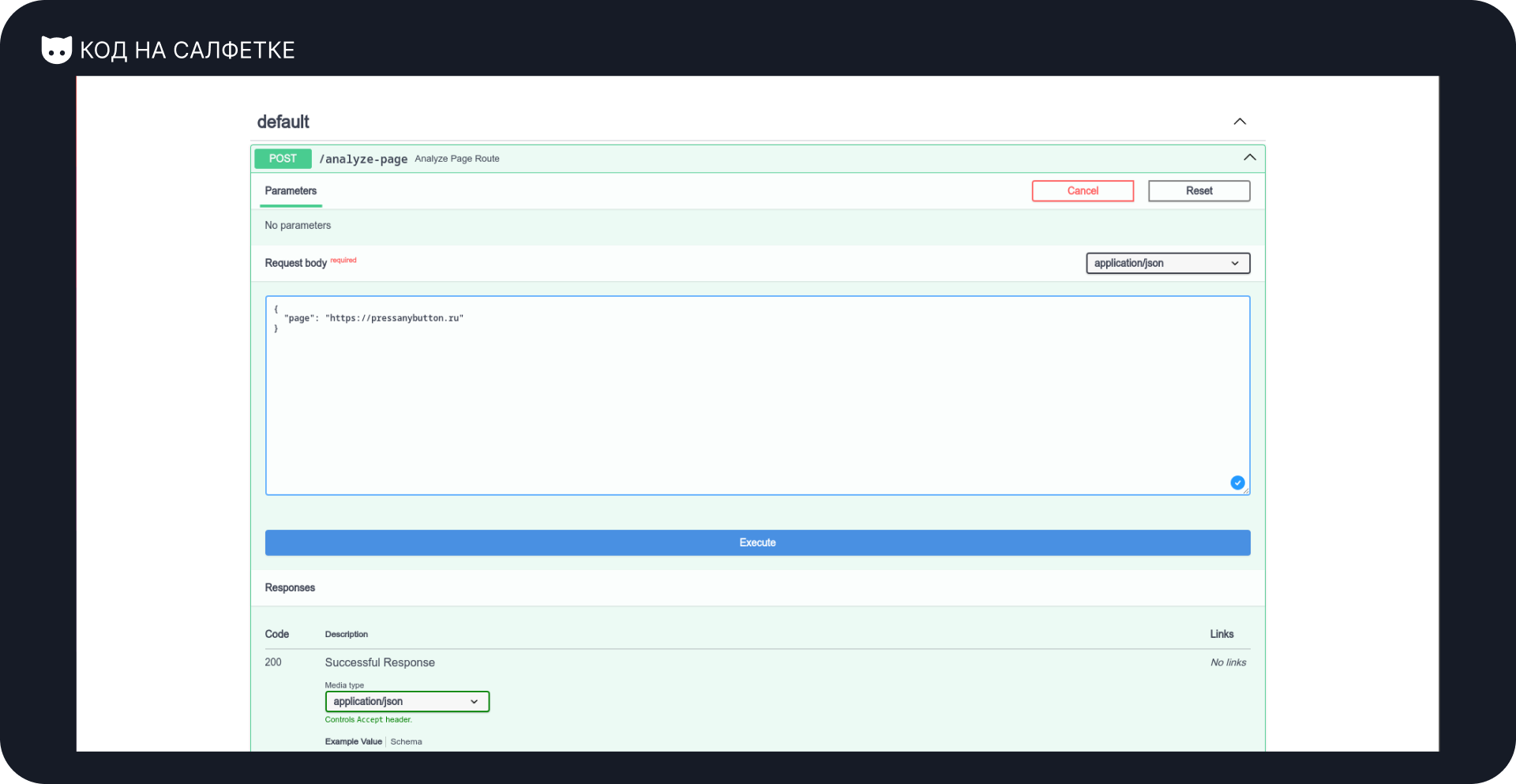
Момент истины: сработает ли? Будет ли ошибка?
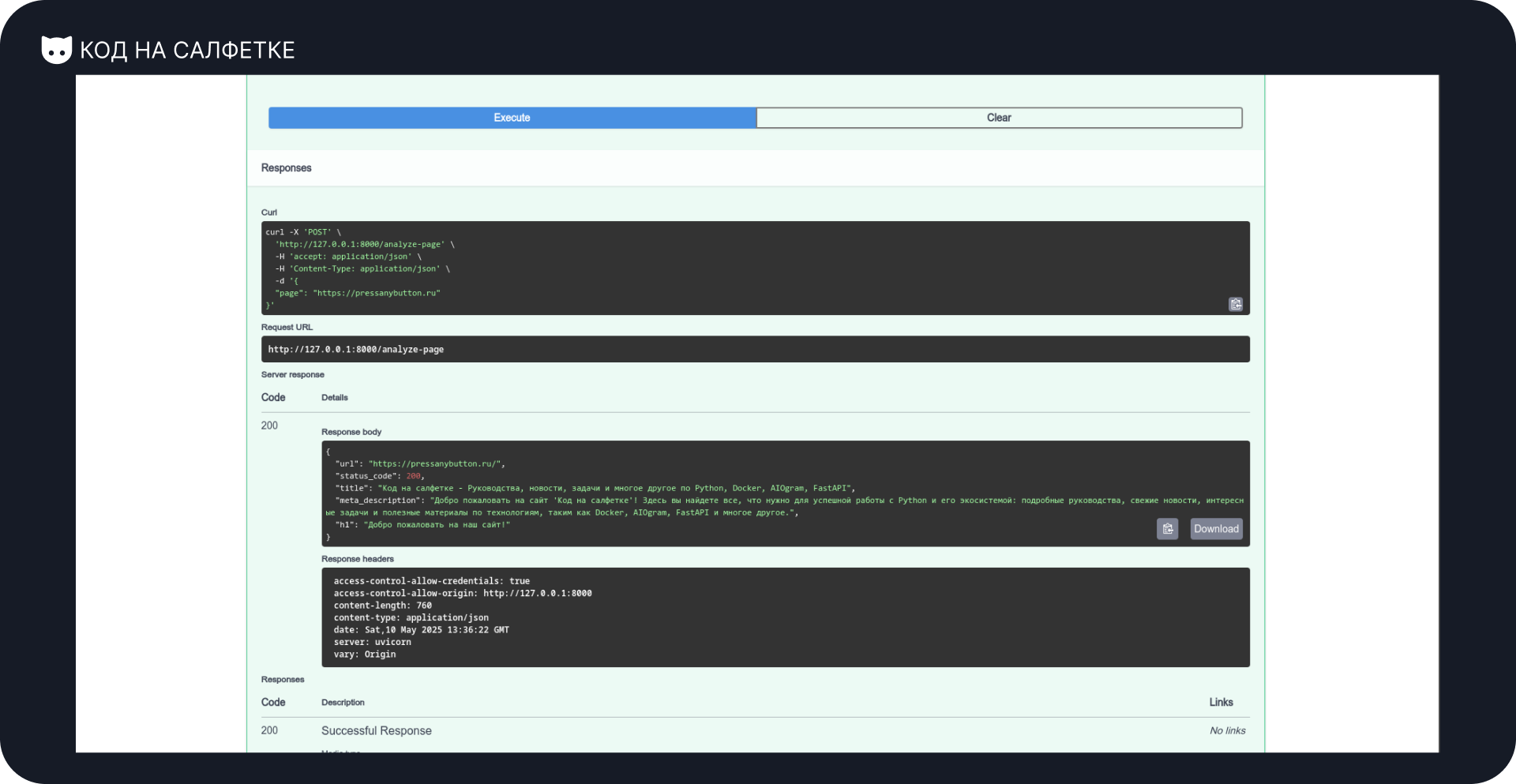
И — удивительно! Ошибок нет. Более того — ответ корректный и полный:
{
"url": "https://pressanybutton.ru/",
"status_code": 200,
"title": "Код на салфетке - Руководства, новости, задачи и многое другое по Python, Docker, AIOgram, FastAPI",
"meta_description": "Добро пожаловать на сайт 'Код на салфетке'! Здесь вы найдете все, что нужно для успешной работы с Python и его экосистемой: подробные руководства, свежие новости, интересные задачи и полезные материалы по технологиям, таким как Docker, AIOgram, FastAPI и многое другое.",
"h1": "Добро пожаловать на наш сайт!"
}Результат — выше ожиданий. Работает с первого запроса.
Проверяем историю запросов
Анализ страницы сработал отлично. Теперь проверим, сохраняется ли история.
Маршрут /analyze-history не требует параметров, поэтому просто выполняю запрос.
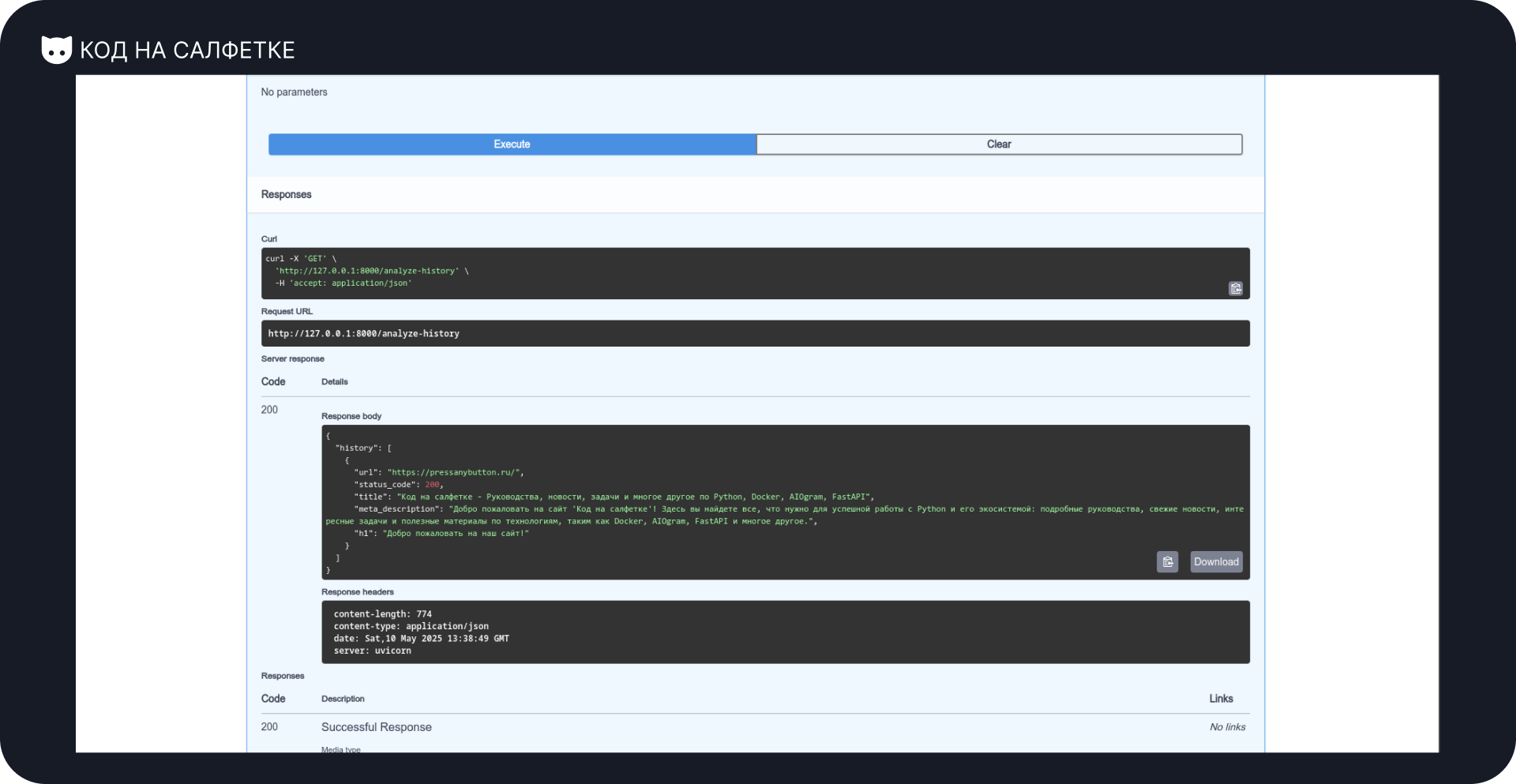
Результат — JSON с ключом history, в котором находится массив предыдущих анализов:
{
"history": [
{
"url": "https://pressanybutton.ru/",
"status_code": 200,
"title": "Код на салфетке - Руководства, новости, задачи и многое другое по Python, Docker, AIOgram, FastAPI",
"meta_description": "Добро пожаловать на сайт 'Код на салфетке'! Здесь вы найдете все, что нужно для успешной работы с Python и его экосистемой: подробные руководства, свежие новости, интересные задачи и полезные материалы по технологиям, таким как Docker, AIOgram, FastAPI и многое другое.",
"h1": "Добро пожаловать на наш сайт!"
}
]
}Всё на месте: URL, статус, заголовки, описание, h1 — всё сохранилось корректно. А главное — без участия человека (почти). Отличный результат!
Что накодил ИИ?
Как видим, прототип проекта получился вполне-себе-рабочим, но интересно, что же написала нейронка?
Я пойду по файлам и буду писать своё субъективное мнение, описывая, что мне понравилось или нет.
README.md
Начну с "лица" проекта, то есть с его README.md файла.

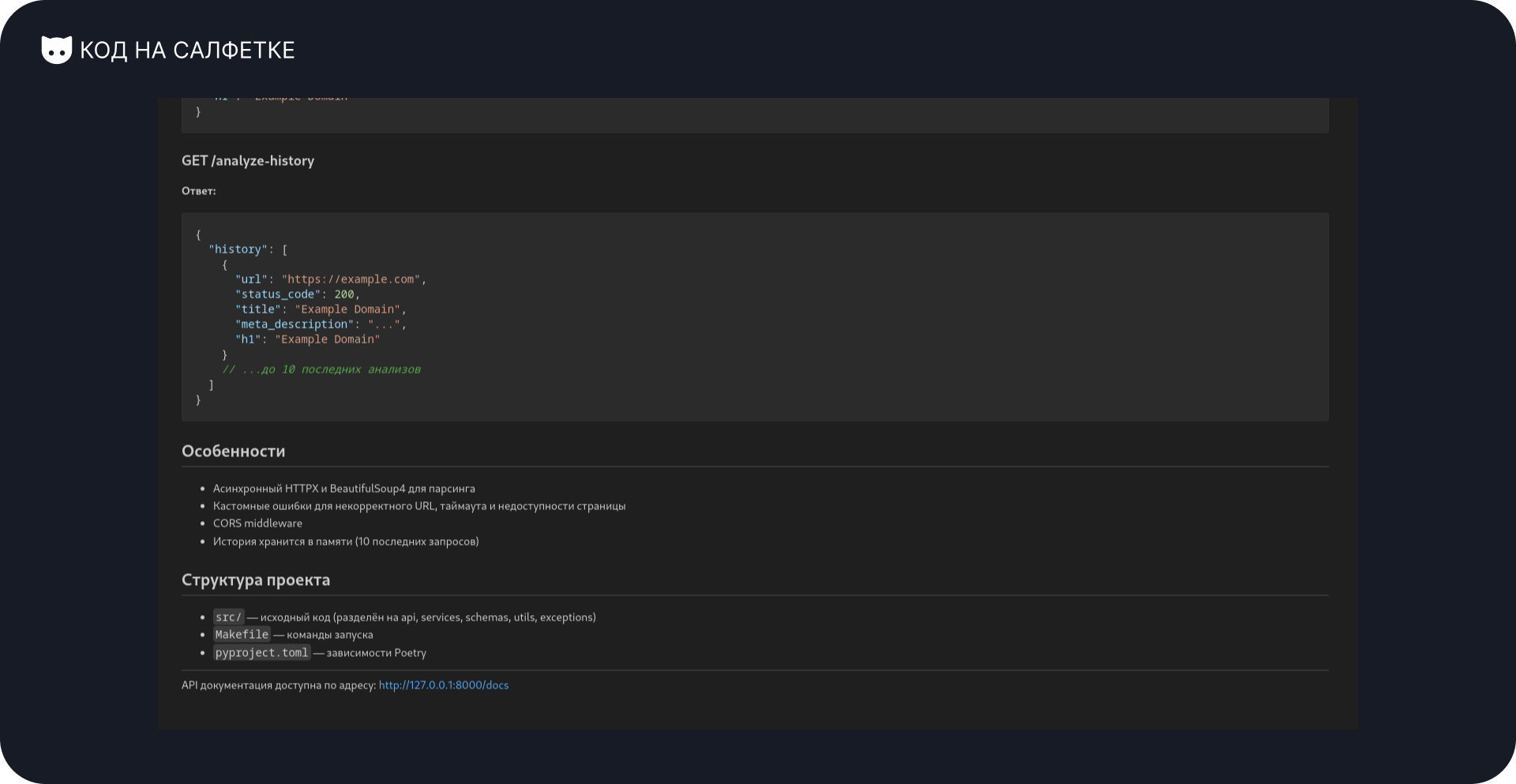
Получился весьма достойный "ридмик":
- Название и краткое описание проекта.
- Инструкция по запуску.
- Примеры запросов.
- Особенности и структура проекта.
Всё это есть минимально, но этого вполне достаточно. Есть множество репозиториев где авторы пренебрегают даже минимальной информацией для заинтересованных.
pyproject.toml
[project]
name = "ai-test-one"
version = "0.1.0"
description = ""
authors = [
{name = "proDream",email = "sushkoos@gmail.com"}
]
readme = "README.md"
requires-python = ">=3.12"
dependencies = [
"fastapi (>=0.115,<0.116)",
"httpx[http2] (>=0.28.1,<0.29.0)",
"beautifulsoup4 (>=4.13.4,<5.0.0)",
"uvicorn (>=0.34.2,<0.35.0)",
"pydantic (>=2.11.4,<3.0.0)"
]
[build-system]
requires = ["poetry-core>=2.0.0,<3.0.0"]
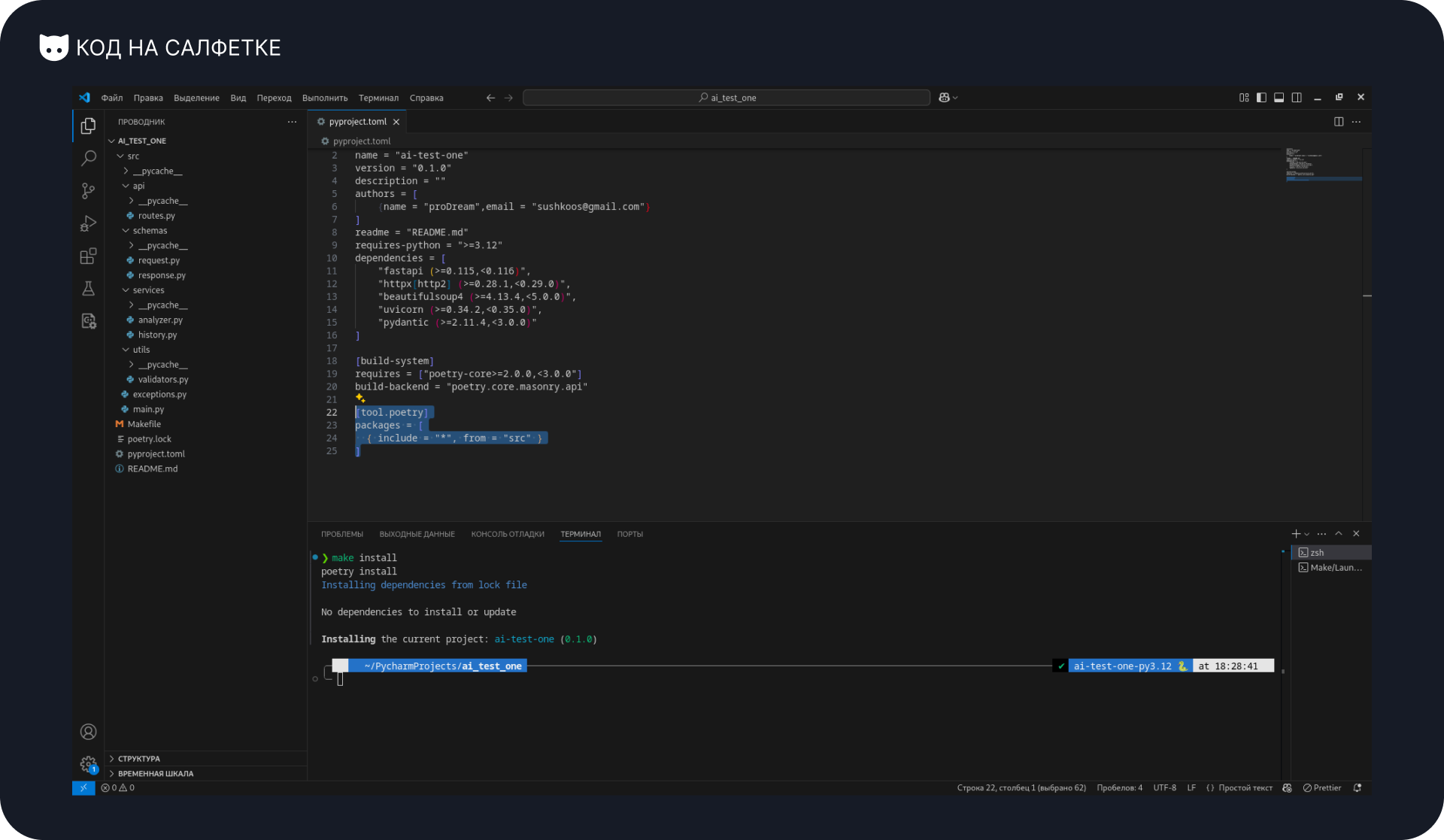
build-backend = "poetry.core.masonry.api"Тут практически никаких нареканий. Единственное, что нет указания на то, что файлы проекта находятся в директории src, хотя по правилам poetry, должны быть в пакете ai-test-one или ai_test_one.
Из-за этого будет ошибка при выполнении команды poetry install:
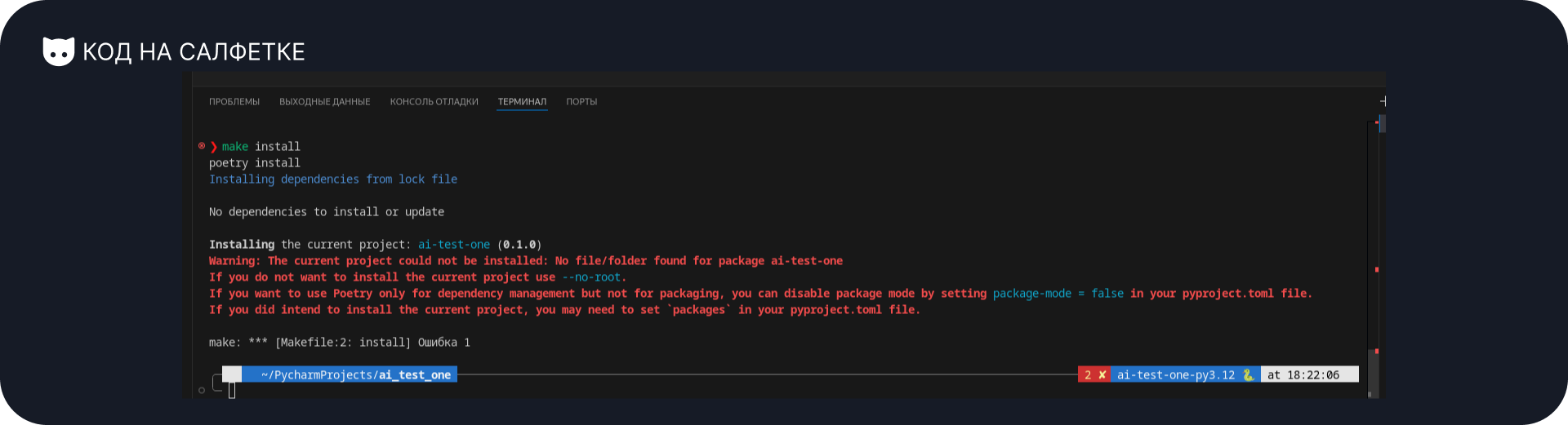
Как это исправить?
Достаточно добавить в файл новый блок [tool.poetry] с указанием на то, где искать файлы проекта:
[tool.poetry]
packages = [
{ include = "*", from = "src" }
]
Makefile
install:
poetry install
run:
poetry run uvicorn src.main:app --reloadТут всё более чем корректно.
Команда make install выполнит инициализацию проекта с установкой зависимостей, а команда make run запустит веб-сервер uvicorn.
src/main.py
Перехожу к "точке входа" в приложение.
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from src.api.routes import router
app = FastAPI(title="Web Page Analyzer API")
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
app.include_router(router)Достаточно стандартная ситуация:
- Инициализирован объект FastAPI в переменной
app, которую и "подхватывает"uvicornпри запуске. - Добавлен CORS-middleware в стандартном виде.
- Подключен роутер
routerиз модуля маршрутов.
Мне больше нравится вариант обёрнутый в функцию, нежели просто так в коде, но указаний на это не было, поэтому ИИ написал так, как пишут "чаще всего".
src/exceptions.py
from fastapi import HTTPException, status
class InvalidURLException(HTTPException):
def __init__(self, detail: str = "Некорректный URL"):
super().__init__(status_code=status.HTTP_422_UNPROCESSABLE_ENTITY, detail=detail)
class PageUnavailableException(HTTPException):
def __init__(self, detail: str = "Страница недоступна"):
super().__init__(status_code=status.HTTP_502_BAD_GATEWAY, detail=detail)
class PageTimeoutException(HTTPException):
def __init__(self, detail: str = "Таймаут запроса к странице"):
super().__init__(status_code=status.HTTP_504_GATEWAY_TIMEOUT, detail=detail)В этом файле описаны собственные исключения. Все они наследуются от стандартного для FastAPI HTTPException.
Ничего сверхъестественного. Единственное, что мне не нравится, это расположение файла в корне. Я бы поместил его в специальный пакет где были бы модули для разных ситуаций, но поскольку проект очень маленький, достаточно и этого.
src/api/routes.py
from fastapi import APIRouter, Depends
from src.schemas.request import AnalyzePageRequest
from src.schemas.response import AnalyzePageResponse, AnalyzeHistoryResponse
from src.services.analyzer import analyze_page
from src.services.history import add_to_history, get_history
from src.utils.validators import validate_url
router = APIRouter()
@router.post("/analyze-page", response_model=AnalyzePageResponse)
async def analyze_page_route(request: AnalyzePageRequest):
url = validate_url(str(request.page))
result = await analyze_page(url)
add_to_history(result)
return result
@router.get("/analyze-history", response_model=AnalyzeHistoryResponse)
def analyze_history_route():
history = get_history()
return AnalyzeHistoryResponse(history=history)Меня смущает то, что хоть я ему и сказал выносить логику маршрутов в сервис, он оставил тут много действий. Я больше придерживаюсь того, чтобы вызывать в маршруте сервис, который будет выполнять все необходимые действия, а маршрут будет только возвращать результат (если не был райзнут эксепшен).
Примерно вот так бы это выглядело у меня в коде:
# src/api/routes.py
@router.post("/analyze-page", response_model=AnalyzePageResponse)
async def analyze_page_route(data: AnalyzePageRequest, service: AnalyzerService = Depends(AnalyzerService)) -> AnalyzePageResponse:
return await service.analyze_page(data=data)
# src/api/service.py
class AnalyzerService:
# __init__.py и другое
async def analyze_page(data: AnalyzePageRequest) -> AnalyzePageResponse:
url = validate_url(url=str(request.page))
result = await analyze_page(url=url)
add_to_history(item=result)
return resultНе указана аннотация возвращаемых типов -> ..., и почему-то во втором маршруте он указал history=history, а в первом в вызовах передаёт позиционные аргументы.
Однако, если опустить эти недочёты, написано достаточно корректно:
- Есть декораторы с указанием пути и модели ответа.
- Выполняется определённая логика.
- Возвращается ответ.
src/schemas/request.py и src/schemas/response.py
src/schemas/request.py
from pydantic import BaseModel, HttpUrl, Field
class AnalyzePageRequest(BaseModel):
page: HttpUrl = Field(..., description="URL для анализа")src/schemas/response.py
from pydantic import BaseModel, HttpUrl
from typing import Optional
class AnalyzePageResponse(BaseModel):
url: HttpUrl
status_code: int
title: Optional[str]
meta_description: Optional[str]
h1: Optional[str]
class AnalyzeHistoryResponse(BaseModel):
history: list[AnalyzePageResponse]Что понравилось:
- Схемы описаны корректно
- Он разделил входные и выходные схемы по разным файлам
- Использовал в схеме
AnalyzeHistoryResponseимеющуюся схемуAnalyzePageResponse
Что не понравилось:
- Я не спроста указал на использование Python 3.12+. Использование
typingчастично отходит на второй план, вместоOptional[str]достаточно написатьstr | None, но он это проигнорировал. - В модели
AnalyzePageRequestон дал описание полю, в других моделях нет. Это не суть важно, конечно, но теряется единообразие кода.
src/services/analyzer.py
import httpx
from bs4 import BeautifulSoup
from src.schemas.response import AnalyzePageResponse
from src.exceptions import PageUnavailableException, PageTimeoutException
async def analyze_page(url: str) -> AnalyzePageResponse:
try:
async with httpx.AsyncClient(timeout=10) as client:
response = await client.get(url)
except httpx.TimeoutException:
raise PageTimeoutException()
except httpx.RequestError:
raise PageUnavailableException()
status_code = response.status_code
if status_code >= 500:
raise PageUnavailableException(f"Ошибка сервера: {status_code}")
html = response.text
soup = BeautifulSoup(html, "html.parser")
title = soup.title.string.strip() if soup.title and soup.title.string else None
meta = soup.find("meta", attrs={"name": "description"})
meta_description = meta["content"].strip() if meta and meta.get("content") else None
h1_tag = soup.find("h1")
h1 = h1_tag.get_text(strip=True) if h1_tag else None
return AnalyzePageResponse(
url=url,
status_code=status_code,
title=title,
meta_description=meta_description,
h1=h1
)Достаточно большой блок включающий в себя несколько действий:
- Открывается контекстный менеджер с клиентом HTTPX
- Выполняется получение страницы
- Проверяется статус-код выполненного запроса
- Выполняется парсинг страницы для получения данных
- Возвращается Pydantic-схема
Можно сказать, что тут всё выглядит неплохо, но!
Во первых, блок try-except можно вовсе исключить отсюда, добавив в проект глобальный хэндлер ошибок. Подробнее об этом я писал в статье "Taigram: универсальная клавиатура и исключения". Так код был бы чище, а обработка ошибок централизованной.
Во вторых, процесс выполнения запроса я бы поместил в отдельный класс для выполнения запросов, а процесс парсинга в утилитарную функцию в пакете utils, оставив в сервисе только вызовы запроса, парсинга и формирования данных. Это бы позволило разделить ответственность за разные операции по "логическим" блокам.
В третьих, вместо html.parser лучше использовать lxml-парсер. lxml быстрее работает, лучше "переваривает" плохо форматированный HTML, а также поддерживает сложные CSS-селекторы и XPath. Вероятно, он взял его потому, что в промпте не был указан пакет lxml и решил, что достаточно встроенного решения.
src/services/history.py
from collections import deque
from threading import Lock
from src.schemas.response import AnalyzePageResponse
# Очередь с ограничением длины для хранения истории
_history = deque(maxlen=10)
_lock = Lock()
def add_to_history(item: AnalyzePageResponse):
with _lock:
_history.appendleft(item)
def get_history() -> list[AnalyzePageResponse]:
with _lock:
return list(_history)Честно, я думал, что он просто использует глобальный list или что-то вроде того, но он поступил "умнее".
Что тут происходит?
- В переменной
_historyхранится объект коллекцииdeque(двусторонняя очередь). Аргументmaxlen=10, автоматически удаляет старые записи при добавлении новых. - В переменной
_lockхранится объектLockиз модуляthreading, обеспечивающий безопасность работы с очередью. - В функции
add_to_historyоткрывается контекстный менеджер "блокировки", чтобы заблокировать взаимодействие с очередью в данный момент времени. Затем используется метод.appendleft()для добавления записи в начало очереди. - В функции
get_historyтакже выполняется блокировка очереди. После чего очередь преобразуется к списку и возвращается.
Решение, бесспорно, интересное и вполне соответствует поставленному ТЗ, а именно хранению данных в оперативной памяти.
src/utils/validators.py
from urllib.parse import urlparse
from src.exceptions import InvalidURLException
def validate_url(url: str):
parsed = urlparse(url)
if not (parsed.scheme in ("http", "https") and parsed.netloc):
raise InvalidURLException("URL должен начинаться с http(s):// и содержать домен")
return urlВ этом файле происходит проверка переданного адреса страницы на корректность.
Достаточно стандартная функция. Разве, что я бы располагал этот файл не в пакете utils, а как раз в отдельном пакете validators, с указанием в названии файла его принадлежности к валидации URL, например, url_validator.py.
Оценка результата
Функциональная полнота
Оценка:
- Все пункты выполнены.
Качество кода
Оценка:
- Простая модульность, но в общем и целом соответствует ТЗ.
- Замечания:
- ИИ не предусмотрел настройку Poetry для использования
src-структуры проекта. - Отсутствие типизации
str | NoneвместоOptional[str](игнорирование Python 3.12+). - Использование
html.parserвместо более эффективногоlxml.
- ИИ не предусмотрел настройку Poetry для использования
Архитектурные решения
Оценка:
- Базовая архитектура имеет место быть. Вероятно в будущем стоит более точно прописывать этот момент в промпте.
- Замечания:
- Отсутствие глобального обработчика ошибок (вместо повторения try-except в analyzer.py).
- Недостаточное разделение ответственности в маршрутах (можно вынести логику в сервисы).
Документация и инструкции
Оценка:
- Минимальная документация и простой (достаточный) Makefile.
- Замечания:
- Отсутствие описания ответов при ошибках.
- Отсутствие докстрингов во всём проекте.
- Аннотация типов присутствует частично.
Эффективность и время
Оценка:
- Справился быстро, но требуется доработка.
- С написанием основного промпта помог DeepSeek. С небольшими правками на это ушло минут 5-10.
- На всё взаимодействие с агентом ушло минут 10.
- На анализ результата ушло минут 5 (и несколько часов на описание для вас!).
- На исправление запуска ушло несколько минут.
- На доработку проекта под удовлетворяющую меня структуру уйдёт ещё до получаса.
- Итого: на написание этого проекта ушло примерно 25 минут.
Резюме эксперимента
На всё про всё ушло минут 25 (писать всё это было куда дольше) и 10 взаимодействий с агентом, из них: 3 - это сообщения агенту и 7 нажатие клавиши "продолжить".
В результате я получил рабочий, но не лишённый минусов прототип. Если навести порядок в файлах и продолжить развитие проекта, например, добавив хранение в БД, может выйти достаточно интересный и простой в написании сервис (может внедрить его в функционал будущего lkeep, что думаете?).
Уверен, что часть комментариев будет из разряда "да я сам такое напишу быстрее и будет лучше, давай что-то сложнее и комплекснее" и я с вами соглашусь.
Поэтому, предлагаю вам решить, что будет в следующей статье. Можно попробовать сделать что-то другое, крупнее или продолжить дорабатывать этот проект.
Единственное давайте "на берегу" оговорим ограничения:
- Проект должен быть на Python.
- Не пишем фронтэнд, только бэк, только питон.
- Не используем специфические для больших проектов вещи, например, Kubernetes или Kafka.
Мне будет приятно, если вы примете участие в обсуждении, а также положительно оцените статью.
Всё в ваших руках! Благодарю за внимание.

Комментарии
Оставить комментарийВойдите, чтобы оставить комментарий.
Комментариев пока нет.